

過学習
過学習
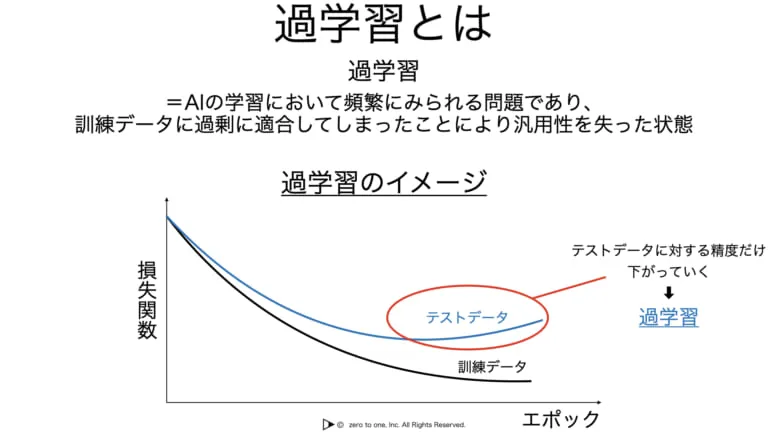
過学習とは、AIの学習において頻繁に見られる問題であり、訓練データに過剰に適合してしまったことにより汎用性を失った状態のことを指します。
👉より体系的に学びたい方は「人工知能基礎」(東京大学松尾豊先生監修)へ
クイズ
以下の文章を読み、空欄(ア)に最もよく当てはまる選択肢を1つ選べ。
(ア)は訓練データの不足に起因していることが殆どである。
(参考:深層学習 P35)
- Check Answer
- Explanationこの問題は、訓練データの不足が主要の原因となる最も適切な選択肢を選ぶ問題です。 未学習は、モデルが単純すぎたり、学習回数(エポック数)が不足していたりすることで、訓練データのパターンすら十分に学習出来ていない状態です。 具体的には、リンゴを認識するタスクで、モデルのパラメータ数や学習回数が不足していて、「丸い」「赤い」といった基本的な特徴すらも捉えられない場合に発生します。 訓練データが少なくても、モデルの複雑さや学習回数が適切だった場合、その少数の訓練データのパターンは学習可能です。つまり、未学習は訓練データの不足によって引き起こされません。 対して、過学習は、モデルが訓練データに最適化されすぎて、未知のデータに対して汎化できない(性能を発揮できない)ことです。これは主に訓練データの不足によって発生します。 具体的には、訓練データに特定のリンゴの画像のみが数枚だけ含まれていた場合、モデルが「この特定のリンゴの形・色・向き」などの個別の特徴を学習することで、テストデータの少し違うリンゴの画像をリンゴと正しく認識できないケースなどです。 過学習は、モデルが複雑すぎる場合にも発生することがありますが、それも訓練データの不足と捉えることが出来ます。 複雑なモデルでも、十分な訓練データを与えることで、汎化性能が向上します(OpenAIのGPTモデルのパラメータ数は膨大ですが、大規模なデータを学習することで汎化を実現しています)。 内容をまとめると、 ・未学習:モデルの表現力不足が主因(データを増やしても改善しない) ・過学習:データ不足が主因(データを増やせば改善する) この問題では「データ不足が主因」という観点から、過学習が正解となります。
 (参考: G検定公式テキスト 第3版,p.24,100,150,151,155)
(参考: G検定公式テキスト 第3版,p.24,100,150,151,155)👉G検定の受験対策は約1,000問収録の「G検定実践トレーニング」へ
人工知能基礎講座を提供中
人工知能の第一人者である東京大学の松尾豊教授が監修した人工知能基礎講座を受講してみませんか?
人工知能の歴史から自然言語処理、機械学習、深層学習といった最先端のトピックやAIに関わる法律問題まで網羅しているので全てのビジネスパーソン・AIの初学者におすすめです。
サンプル動画
人工知能基礎講座はこちら↓

AI初学者・ビジネスパーソン向けのG検定対策講座
G検定受験前にトレーニングしたい方向けの問題集「G検定実践トレーニング」も提供中です。

zero to oneの「E資格」向け認定プログラム
日本ディープラーニング協会の実施するE資格の受験ならzero to oneの「E資格」向け認定プログラム (税込165,000円) をおすすめします。当講座は、東京大学大学院工学系研究科の松尾豊教授と東北大学大学院情報科学研究科の岡谷貴之教授が監修する実践的なプログラムとなっています。
厚生労働省の教育訓練給付制度対象のE資格認定プログラムの中では最安値※となり、実質負担額49,500円~(支給割合70%の場合)で受講可能です。※2023年弊社調べ
