

Text-To-Image
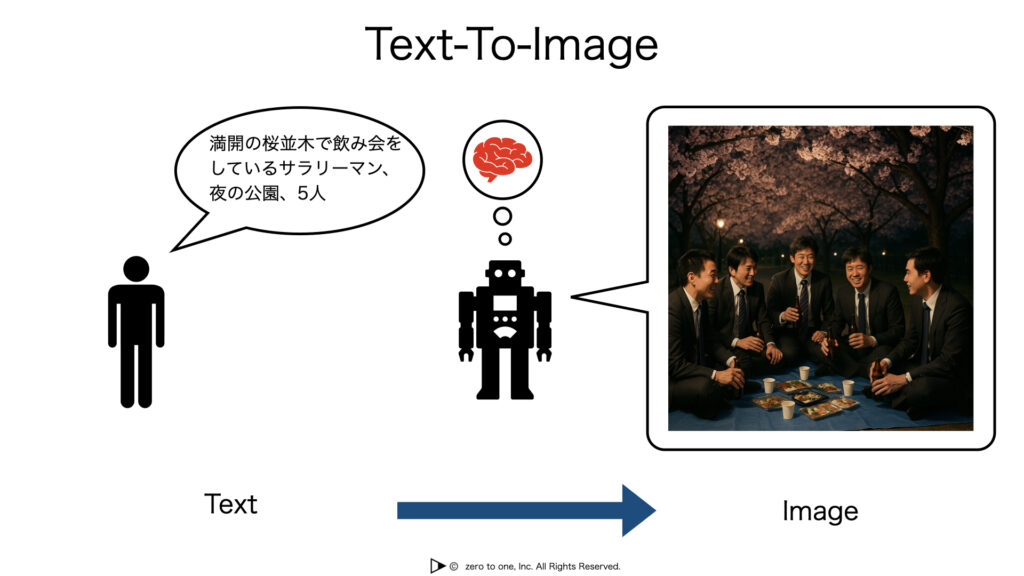
Text-To-Image は、自然言語で与えられた指示や説明文をもとに、対応する画像を生成するタスクです。 Image Captioningと対になるようなタスクです。
この技術の学習には、大規模なテキストと画像の対応データが活用され、テキスト情報を視覚的に解釈し、画像として再構成できるマルチモーダルモデルが構築されます。適切にファインチューニングを行うことで、スタイルの制御や構図の調整といった細かな要望にも対応できるようになり、より自然で高品質な画像生成が可能になります。 また、Text-To-Image はマルチモーダルAIの代表的な応用例の一つであり、デザインや広告、教育、ゲームコンテンツ制作など多様な分野に活用されています。
👉より体系的に学びたい方は「人工知能基礎」(東京大学松尾豊先生監修)へ
Text-To-Image の説明として正しいものを選べ。
人工知能基礎講座を提供中
人工知能の第一人者である東京大学の松尾豊教授が監修した人工知能基礎講座を受講してみませんか?
人工知能の歴史から自然言語処理、機械学習、深層学習といった最先端のトピックやAIに関わる法律問題まで網羅しているので全てのビジネスパーソン・AIの初学者におすすめです。
サンプル動画
人工知能基礎講座はこちら↓

AI初学者・ビジネスパーソン向けのG検定対策講座
G検定受験前にトレーニングしたい方向けの問題集「G検定実践トレーニング」も提供中です。

zero to oneの「E資格」向け認定プログラム
日本ディープラーニング協会の実施するE資格の受験ならzero to oneの「E資格」向け認定プログラム (税込165,000円) をおすすめします。当講座は、東京大学大学院工学系研究科の松尾豊教授と東北大学大学院情報科学研究科の岡谷貴之教授が監修する実践的なプログラムとなっています。
厚生労働省の教育訓練給付制度対象のE資格認定プログラムの中では最安値※となり、実質負担額49,500円~(支給割合70%の場合)で受講可能です。※2023年弊社調べ
