


*この記事は「さくらのAI検定( https://www.sakura.ad.jp/ai-certification/ )」教材として作成しています。
ここでは、音声データをテキスト化する音声文字起こしAPIの基本的な使い方を理解し、音声データを生成AIで活用できる形に整えるまでの流れを学習します。
会議の録音やインタビュー音声など、音声のままでは検索・分析・要約が難しいデータに対して、まず音声をテキストへ変換する必要があることを確認し、さくらのAI Engineが提供する音声文字起こしAPIを用いた処理手順を学習します。
また、長時間音声を扱う場面を想定し、音声ファイルの分割などを含む実用的な文字起こし方法を理解します。さらに、取得した文字起こし結果をチャット用APIで要約し、読みやすいサマリーとして活用するまでの一連の流れを体験します。
音声文字起こしAPIの実行
ここでは、さくらのAI Engineが提供する音声文字起こしAPIを利用し、音声ファイルをテキスト化する手順を確認します。
事前準備
音声文字起こしAPIを利用するにあたり、以下を準備します。
- さくらのAI Engineのアカウントトークン
- 文字起こし対象となる音声ファイル(例:MP3形式)
音声ファイルは、ボイスレコーダーなどで自分の声を録音して作成できます。
手元に音声ファイルがない場合は、さくらのクラウドのオブジェクトストレージに格納してあるサンプル音声ファイルを下記URLからダウンロードして利用してください。
- https://s3.tky01.sakurastorage.jp/ai-kentei/ai-engine_voice.mp3
- https://s3.tky01.sakurastorage.jp/ai-kentei/ai-engine_voice_long.mp3
APIエンドポイント
音声文字起こしAPIでは、以下のエンドポイントを使用します。
POST https://api.ai.sakura.ad.jp/v1/audio/transcriptions
本APIは同期型で動作し、リクエスト完了後に文字起こし結果がレスポンスとして返却されます。
リクエストの作成
APIリクエストは、multipart/form-data形式で送信します。
主に指定する項目は以下のとおりです。
- file:文字起こし対象の音声ファイル(例としてai-engine_voice.mp3を使用)
- model:使用するモデル(whisper-large-v3-turbo)
ターミナルまたはコマンドプロンプトを起動し、アカウントトークンを環境変数に設定してください。
export AI_ENGINE_TOKEN="<発行したアカウントトークン>"※トークンは<uuid:シークレット>形式のまま指定します。
文字起こし対象となる音声ファイルを、curlコマンドを実行するディレクトリに配置してください。
今回は音声ファイルsample.mp3がcurlコマンドを実行するディレクトリに配置されているとします。
(別の場所にある場合は、ファイルのパスを指定することで実行できます。)
次のcurlコマンドを実行し、音声文字起こしAPIを呼び出します。
curl --request POST \
--url https://api.ai.sakura.ad.jp/v1/audio/transcriptions \
--header 'Accept: application/json' \
--header "Authorization: Bearer ${AI_ENGINE_TOKEN}" \
--header 'Content-Type: multipart/form-data' \
--form 'file=@ai-engine_voice.mp3' \
--form 'model=whisper-large-v3-turbo'<リクエストパラメータの概要>
file:文字起こし対象の音声ファイル
model:音声認識に使用するモデル
(本例では whisper-large-v3-turbo を指定)
レスポンスの確認
コマンドを実行すると、以下のようなレスポンスが返却されます。
{
"text": "(音声内容が文字起こしされたテキスト)",
"model": "whisper-large-v3-turbo"
}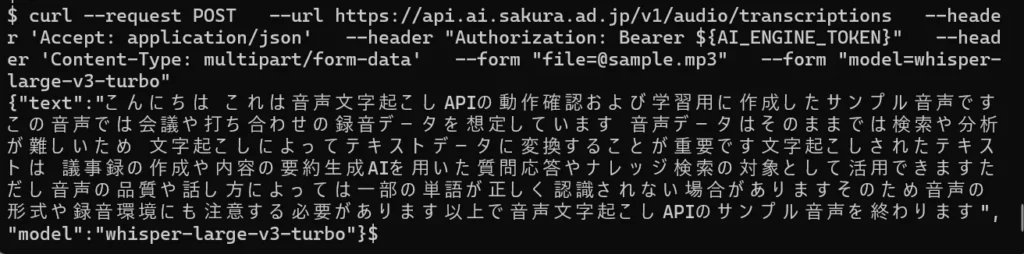
text には、音声ファイルの内容が文字起こしされたテキストが格納されます。
このレスポンスが返却されれば、音声文字起こしAPIの実行は成功です。
文字起こし精度について
音声文字起こしによって得られるテキストは、句読点や改行が少なく、話し言葉がそのまま出力される傾向があります。
また、音声文字起こしAPIは、すべての音声内容を完全に文字起こしできることを保証するものではなく、話者の話し方、録音環境、音質、専門用語の有無などの要因によって、
一部の単語が誤って認識される場合があります。
このため、音声文字起こし結果はそのまま最終成果物として利用するのではなく、生成AIを用いた整形や要約、内容確認を前提として扱うことが重要です。
音声文字起こしAPIは、生成AIを活用するための前処理として位置づけて利用することで、より実用的な議事録作成や情報活用につなげることができます。
本教材に含まれるサンプル音声は、教材作成者本人による録音です。
当該音声は、Creative Commons Attribution 4.0 International(CC BY 4.0)ライセンスの下で提供します。

さくらのAI検定について
「さくらのAI検定」は、AIに取り組む企業や AIの学びを深めたい学校の先生、次世代を担う学生など、広範囲に渡るAI人材育成のためにさくらインターネットが設立した検定です。本コースでは、まず AI をさまざまな場面で使いこなすための基本知識を学ぶ「AI基礎」を提供します。そのうえで、さくらインターネットが提供する AI サービスの構成を理解し、さらに多様なハンズオンを通じて AI を実践的に学べる内容となっています。
本教材は、体験と理論を段階的に紐づけ、AIサービスの仕組みと活用方法を体系的に学べる構成としています。
なお、本教材に掲載している内容は、教育目的でその利用方法を紹介するものであり、さくらインターネット株式会社が当該技術の権利を有するもの、または公式に提供・保証するものではありません。
さくらのAI検定「AI実践」 目次
さくらのAI Engine 実践
- さくらのAI Engine 利用開始の手順
- さくらのAI Engine 利用開始の手順
- Playgroundを使ったチャット
- Playgroundを使ったチャット
- ドキュメント連携とRAG
- RAGの概要
- Playgroundを使ったRAGの実行
- APIを使ったRAGの実行
- 音声文字起こしAPI実践
- 音声文字起こしAPIの概要
- 音声文字起こしAPIの実行(本記事)
- 長時間音声の文字起こし
- 文字起こし結果のサマリー作成
- MCP構成設計
- MCPの概要
- MCPを使った外部ツール連携
- クライアントへのMCP Server組み込み
- マルチモーダルAPI実践
- マルチモーダルAPIの概要
- さくらのAI EngineにおけるマルチモーダルAPI
- マルチモーダルAPIを使った画像認識
- さくらの AI Engine料金体系
- さくらのAI Engineにおけるコスト計算の概要
- さくらのAI Engineにおけるコスト設計のポイント
高火力DOK実践
- 高火力DOKの概要
- 高火力DOKの概要
- ノートブックによる画像生成
- ノートブックによる画像生成
- 音声合成
- OpenVoiceを使った音声合成実践
- Open WebUI実践
- Open WebUIを使ったLLM環境の構築
- タスクによる画像生成
- タスクによる画像生成
- LoRA(軽量追加学習)実践
- LoaRAを使った画像生成実践