


今回はGrad-CAM++を超えるとされるScore-CAM(Score-Weighted Class Activation Mapping)について解説します。Score-CAMは、画像分類モデルの「注目している領域」を可視化する手法のひとつです。従来の Grad-CAM などでは「勾配(gradient)」を使って重みを求めていましたが、Score-CAM は勾配を使わず、モデルの出力スコアそのものを使って注目領域を決定します。これにより、ノイズに強く、より安定した可視化結果が得られるのが特徴です。
Contents
Score-CAMとは
Score-CAMはGrad-CAM++より後に登場した手法です。Grad-CAM++は「勾配の大きさがピクセルの重要度に直結する」という前提に基づいて設計されましたが、この前提には疑問の声もありました。
なぜなら、勾配はノイズの影響を受けやすく、モデルの出力に対して必ずしも安定した指標とは言えないからです。そこで、Score-CAMでは勾配を使用せず、出力スコアの変化によって「クラススコアに貢献しているか」を測るアプローチが採用されました。Score-CAMは、勾配を使用しない可視化手法として安定性と解釈性の両立を実現する手法です。
Score-CAMの仕組み
Score-CAMとGrad-CAM++の違いを厳密に説明すると、モデルの各特徴マップの重要度の決定方法です。Grad-CAM++は下記の式のように勾配によって各特徴マップの重要度を決定していました。先ほども説明しましたがこれは勾配の大きさ=重要度という前提を置いていたためです。

一方で、Score-CAMは実際のモデルのスコアによって重みを決定します。以下はScore-CAMの構造を簡易的に表した図です。
Score-CAMでは特徴マップの重要度を決定するため、特徴マップをフィルターとして使用した画像を再度モデルに判定させることで特徴マップの重要度を決定しています。特徴マップを抽出し、元画像サイズまで特徴マップを拡大する作業がPhase1、特徴マップを活用して生成した画像でモデルの性能をテストするがPhase2です。これらを分けて説明していきます。

特徴マップによるフィルター生成
元画像にかけるフィルターは最終畳み込み層の結果を活用して生成されます。
下記の画像はResNetの最終層畳み込み層の結果の1つです。黄色に近いほど値が大きくなっています。このような特徴マップ(今回は7×7)を元画像サイズまでアップサンプリングします。このようにすることでフィルターを作成します。
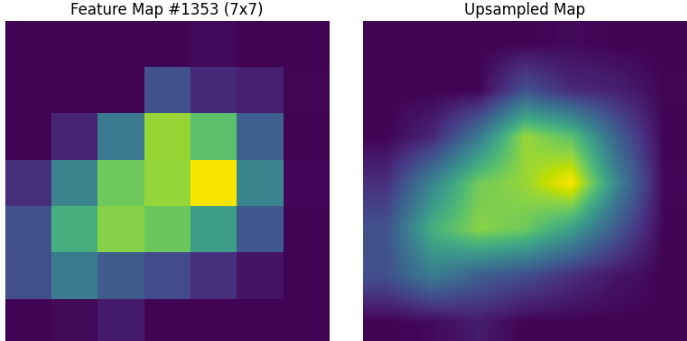
作成したフィルターは値が0~1になるように正規化されています。ここでフィルターと元画像の各ピクセルは1対1関係であるため、フィルターと元画像のピクセルを掛け合わせます。例えば特徴マップで重要とされている部分の値は1に近い値であるため大きな影響を受けませんが、特徴マップが重要ではないと判断した部分は0に近い値となるため、黒になります。このようにして特徴マップを反映した画像を作成するわけです。実際にフィルターを元画像にかけた結果は下記のようになります。

フィルター画像を利用した特徴マップの重要度判定
特徴マップの重要度は各特徴マップを利用して作られたフィルターを通した画像を再びモデルにかけ、得られたスコアに基づいて決定されます。スコアはモデルが推論結果に対してどれほど確信を持っているかだと思ってください。これは、どの特徴マップが最終的なクラス判定に大きく寄与しているかを実際に「モデルが再推論でどれだけスコアを上げるか」で測っているわけです。特徴マップがより特徴を捉えられているほどスコアは良くなるため直感的にも納得のいく指標だと思います。
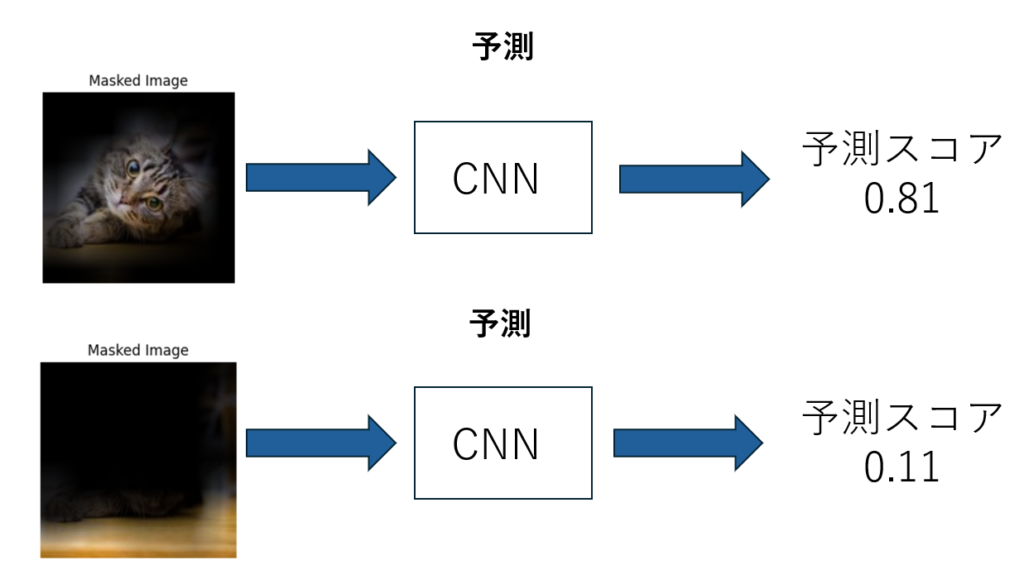
ただし、この手法は特徴マップの数だけ再度モデルが推論を行う必要があります。例えばResNetの場合は2000種類を超える特徴マップが存在するため、ちょっとした学習くらい実行時間がかかるという欠点もあります。
やってみよう
import numpy as np
import tensorflow as tf
import cv2
import matplotlib.pyplot as plt
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions
# モデル準備
base_model = ResNet50(weights="imagenet")
target_layer = base_model.get_layer("conv5_block3_out")
def score_cam(model, image_path, target_layer, class_index=None, alpha_blend=False):
"""
改良版 Score-CAM の実装。
- model: Keras/TensorFlow モデル(例:ResNet50)
- image_path: 画像パス
- target_layer: 最終畳み込み層(例:conv5_block3_out)
- class_index: 対象クラスのインデックス(Noneなら自動推論)
- alpha_blend: True なら、完全な掛け算ではなく αブレンドを試すサンプル
"""
# 1. 画像読み込み & 前処理
original_img = cv2.imread(image_path)
if original_img is None:
raise FileNotFoundError(f"Image not found at {image_path}")
original_img = cv2.cvtColor(original_img, cv2.COLOR_BGR2RGB)
resized_img = cv2.resize(original_img, (224, 224))
input_tensor = preprocess_input(np.expand_dims(resized_img.astype(np.float32), axis=0))
# 2. 特徴マップ取得モデル
activation_model = tf.keras.Model(inputs=model.input, outputs=target_layer.output)
feature_maps = activation_model(input_tensor)[0].numpy() # shape: (H, W, C), e.g. (7, 7, 2048)
H, W, C = feature_maps.shape
# 3. ReLU & 正規化 (0~1) (チャネルごと)
feature_maps = np.maximum(feature_maps, 0)
ch_min = feature_maps.min(axis=(0,1), keepdims=True)
ch_max = feature_maps.max(axis=(0,1), keepdims=True) + 1e-8
feature_maps = (feature_maps - ch_min) / (ch_max - ch_min)
# 4. まずクラスを確定 (class_indexがNoneの場合)
if class_index is None:
preds = model.predict(input_tensor)
class_index = np.argmax(preds[0])
# 5. マスク画像ごとにスコアを算出
weights = []
for i in range(C):
fmap = feature_maps[..., i]
# 4-1. アップサンプリング
fmap_resized = cv2.resize(fmap, (224, 224), interpolation=cv2.INTER_LINEAR)
# 4-2. マスクをかける
# 完全に掛け算する場合
masked_input = input_tensor[0] * fmap_resized[..., np.newaxis]
# もしαブレンド的にしたいならコメントアウトを活用
# alpha = 0.5
# masked_input = alpha * input_tensor[0] + (1 - alpha) * (input_tensor[0] * fmap_resized[..., np.newaxis])
masked_input = np.expand_dims(masked_input, axis=0)
# 4-3. クラススコアを推論
output = model.predict(masked_input)
score = output[0, class_index]
weights.append(score)
weights = np.array(weights)
# デバッグしたい場合は以下をコメントアウト
# print("Score distribution:", weights[:50]) # 上位だけ見てみるなど
# 6. 加重和 (Score-CAM)
cam = np.sum(feature_maps * weights[None, None, :], axis=-1) # shape: (H, W)
cam = np.maximum(cam, 0)
cam = (cam - cam.min()) / (cam.max() - cam.min() + 1e-8)
return cam, original_img
def show_scorecam(image_path, cam_map):
"""
Score-CAM マップを可視化
"""
original = cv2.imread(image_path)
original = cv2.cvtColor(original, cv2.COLOR_BGR2RGB)
heatmap = cv2.resize(cam_map, (original.shape[1], original.shape[0]))
heatmap = np.uint8(255 * heatmap)
heatmap_color = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
heatmap_color = cv2.cvtColor(heatmap_color, cv2.COLOR_BGR2RGB)
overlay = cv2.addWeighted(original, 0.6, heatmap_color, 0.4, 0)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.imshow(original)
plt.title("Original Image")
plt.axis("off")
plt.subplot(1, 2, 2)
plt.imshow(overlay)
plt.title("Score-CAM")
plt.axis("off")
plt.show()
if __name__ == "__main__":
image_path = "" # 画像のパスを入力
cam_map, orig = score_cam(base_model, image_path, target_layer)
show_scorecam(image_path, cam_map)

上記のScore-CAMコードを実行した結果とGrad-CAM++を実行した結果を比較したものです。Score-CAMのほうがやや重要範囲が狭く、重要な部分を絞れているように見えます。皆さんも気になる画像で試してみてください。
Score-CAMの性能比較
下記は”Score-CAM:Score-Weighted Visual Explanations for Convolutional Neural Networks”に記載されていた性能比較の表です。1つずつ解説していきます。

Average Drop
こちらはそれぞれの手法で重要と判断されたピクセルのみを画像解析モデルに与えた際に、どれほど予想精度が低下するかを表したものです。Average Dropが低いほど漏れなく重要領域を可視化できているということです。Grad-CAM++とScore-CAMを比較すると他の手法間よりも大きな差があることが分かると思います。このことからもScore-CAMがどれほど革新的な手法かわかると思います。
Increase in Confidence
こちらは重要領域と判定された以外の部分を隠した画像を用いて分類を行った際にどれほど精度が上昇したかを示すものです。なぜ精度が上がるかというと画像の分類において重要ではない部分を取り除くため誤判定が減るからです。Grad-CAM++とScore-CAMのスコアを比較するとScore-CAMは飛躍的に貢献できてることが分かります。このことからScore-CAMがGrad-CAM++と比較してより分類において重要ではない部分を判別できているということになります。
まとめ
今回はCNNの判断根拠として注目されているScore-CAMについて解説しました。Score-CAMは計算コストが求められる代わりにGrad-CAM++などと比較して高精度な可視化を可能にする手法です。マシーンリソースに余裕がある場合や厳密な可視化画像が必要とされる際に有効な手法となっているのでぜひ使ってみてください。










