


以前の記事では、CLIP (Contrastive Language-Image Pre-training)の仕組みについて解説を行いました。
参考: CLIPとは?画像とテキストを結ぶAI技術をコード付きで徹底解説!
今回は、CLIPが活用されているマルチモーダルモデルについて説明したいと思います!
マルチモーダルモデルとは、複数の異なるデータ形式(モーダリティ)を同時に扱えるAIモデルのことです。例えば、テキスト、画像、音声、動画など、異なる種類の情報を組み合わせて理解し、処理することができます。
ではさっそく本文どうぞ!
1.はじめに
CLIP (Contrastive Language-Image Pre-training) の概要と重要性
CLIPは、画像とテキストを同時に理解できるマルチモーダルなAIモデルです。
このモデルは2つのエンコーダ(入力変換器)で構成されています:
- 画像エンコーダ: 画像を特徴ベクトルに変換する部分(ResNetなどのアーキテクチャを使用)
- テキストエンコーダ: テキストを特徴ベクトルに変換する部分(Transformerを使用)
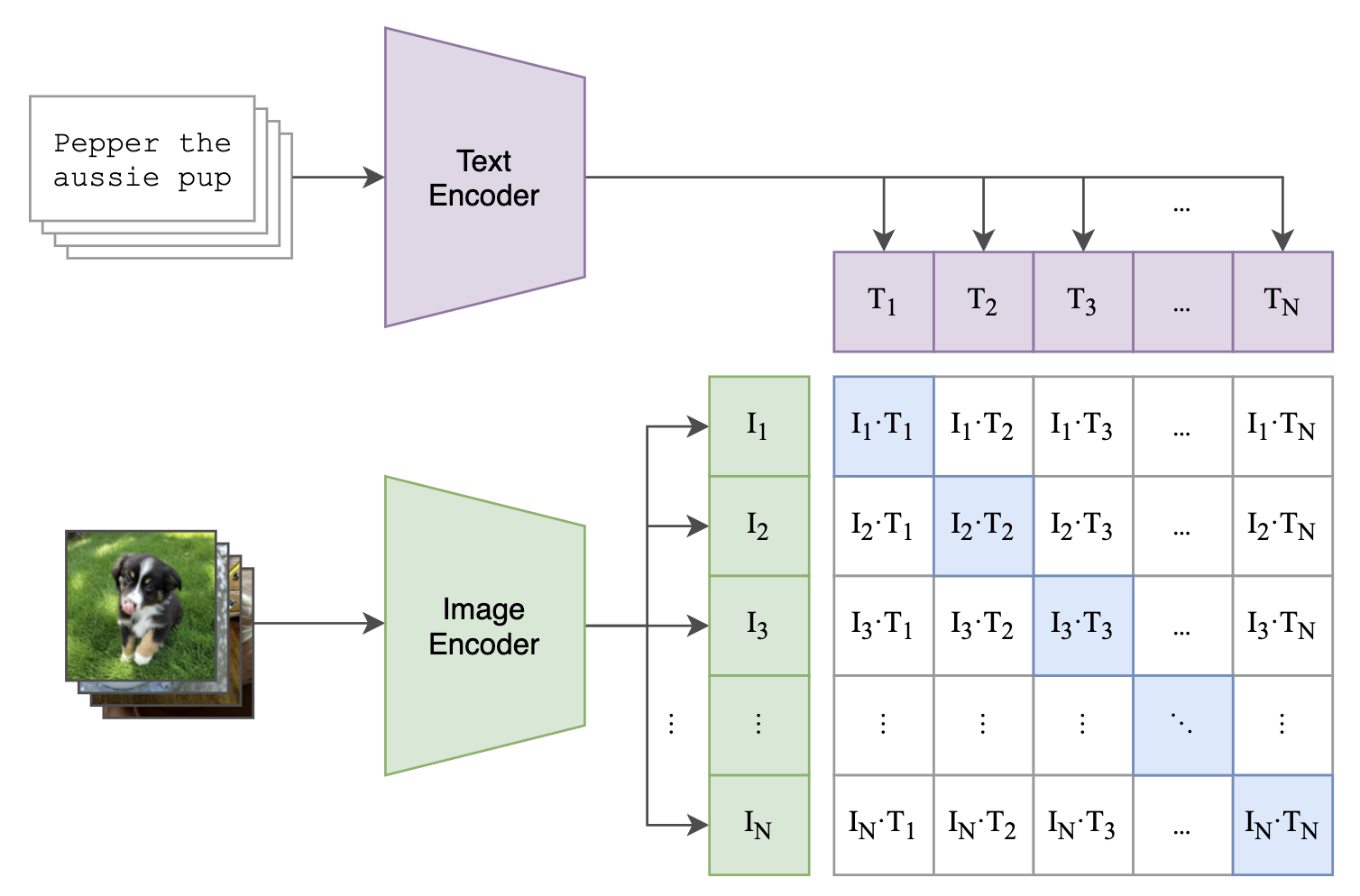
これらのエンコーダは、画像と言語という異なる次元のデータを、共通する特徴空間に埋め込む機能であり、Web上の4億枚の画像とキャプションのペアデータを用いて最適化されています。
CLIPは、画像と言語を上手く結びつけることができるため、多様な下流タスクへの応用が可能です。
例えば、最も有名な例であるゼロショット画像分類や、テキストによる画像検索、逆に画像によるテキスト検索などが挙げられます。
本記事の目的
本記事では、CLIPが活用されている最新のAIモデルについて解説していきます。
CLIPのエンコーダは、画像と言語の特徴を上手く結びつけるため、様々なV&L(Vision & Language)モデルに組み込まれています。今回は、特に画像生成モデルとVLM (Vision-Language Model) に焦点を当て、その特徴と応用事例を紹介していきます。
2.CLIPと画像生成モデル
画像生成モデルにおけるCLIPの役割
画像生成の仕組みについて簡単に説明します。
画像を生成する際には、まず、「プロンプト」と呼ばれるテキストをモデルに入力します。次に、テキストエンコーダを用いて、プロンプト(テキスト)を特徴ベクトルに変換します。そして、テキストの情報を含んだ特徴ベクトルを、デコーダやノイズ除去プロセスを用いて画像に変換します。
以上がとてもざっくりした画像生成の仕組みです。モデルによってエンコーダやデコーダ、内部の処理が異なる点に注意してください!
ここで、CLIPが果たす役割が重要です。CLIPは、画像生成モデル内のテキストエンコーダとしてよく採用されています。画像生成モデルにおけるテキストエンコーダは、入力されたテキストを画像生成デコーダ(image decoder)が理解できる形(特徴ベクトル)に変換する役割があります。
ここで、テキストエンコーダは最終的に生成される画像が入力テキストと一致するように、テキストと画像の特徴を適切に関連付ける必要がありますが、CLIPのテキストエンコーダは、優れた埋め込み性能(テキストと画像を結びつける性能が高い)を持つため、画像生成モデルのテキストエンコーダとして非常に適しています。
さらに、CLIPは生成後の画像がテキストプロンプトにどれだけ適合しているかを評価する役割も果たします。このスコアリングによって、モデルが生成プロセスを調整し、プロンプトにより忠実な画像を生成することが可能になります。
CLIPを使った代表的な画像生成モデル
代表的な画像生成モデルとして、Stable DiffusionとDALL-E 2が挙げられます。
Stable Diffusion
Stable Diffusionは、拡散モデル(Diffusion Model)の一種で、画像生成や編集に特化した先進的なAIモデルです。拡散モデルは、元々ノイズから画像を生成する技術として注目されており、Stable Diffusionはその技術を用いて、テキストプロンプトに基づいた高品質な画像生成を可能にしています。
Stable DiffusionにおいてCLIPは、テキストと画像の関係を橋渡しする重要なコンポーネントとして活用されています。以下にその具体的な役割を述べます:
- プロンプトのエンコード
CLIPのテキストエンコーダが、ユーザーが入力したプロンプト(テキスト)を特徴ベクトルに変換します。この特徴ベクトルは、生成する画像の指針となる情報を含んでいます。 - スコアリング
Stable Diffusionでは、生成された画像がプロンプトに忠実であるかを確認するために、CLIPが生成画像をスコアリングすることがあります。このスコアは生成プロセスの最適化にフィードバックとして利用されます。
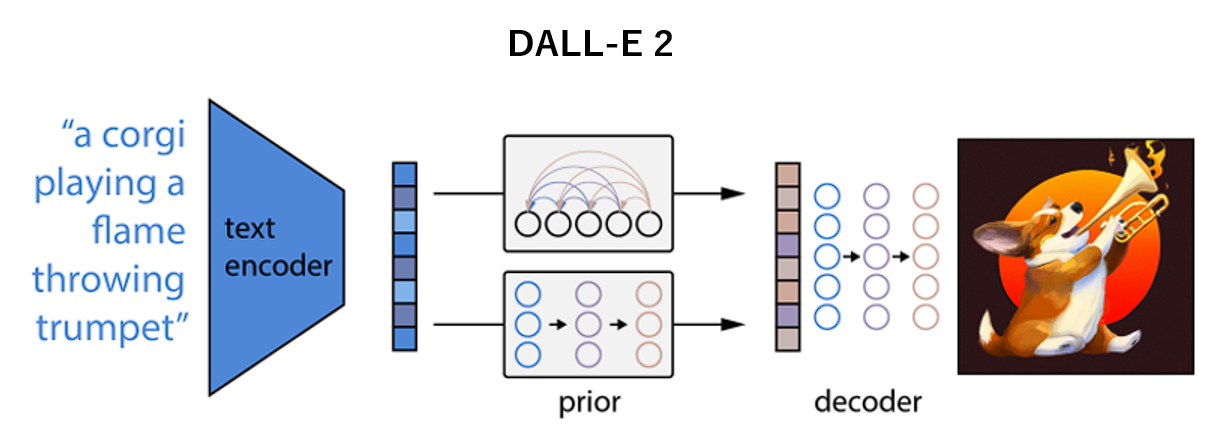
DALL-E 2
DALL-E 2は、OpenAIが開発したテキストプロンプトを基に画像を生成するAIモデルです。初代DALL-Eの進化版であり、創造性と品質が大幅に向上しています。ユーザーが入力した自然言語のプロンプトを解析し、それに対応する独創的で高品質な画像を生成することが可能です。DALL-E 2はアート、デザイン、広告などの分野で広く活用されています。
DALL-E 2ではCLIPが中心的な役割を果たしており、以下のように画像生成プロセスを支えています:
- プロンプトのエンコード
CLIPのテキストエンコーダは、入力されたプロンプトを特徴ベクトルに変換します。このベクトルが、生成プロセスの中核となる「指示」として機能します。 - 画像生成の誘導
DALL-E 2では、CLIPが生成プロセスを誘導する形で活用されます。具体的には、生成される画像がプロンプトに合致するよう、CLIPのテキストと画像のマルチモーダルな理解能力が利用されます。 - 評価と最適化
DALL-E 2は生成された画像がプロンプトとどれだけ一致しているかを評価するために、CLIPを利用します。この評価プロセスは、生成された画像の質を向上させるための重要な要素です。
3.VLM(Vision Language Models)におけるCLIPの活用
VLM (Vision Language Models) とは
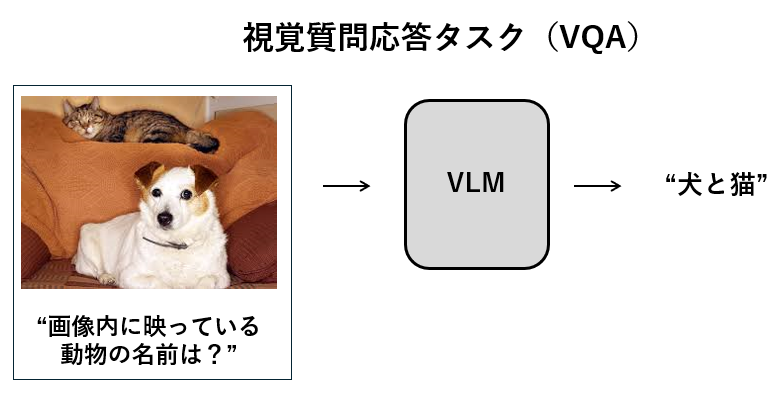
VLMは、画像とテキストを入力として受け取りテキストを出力する生成モデルのことです。LLM(Large Language Models)がテキストのみの入出力に限定されていたのに対し、VLMではテキストと画像というマルチモーダルな情報を扱うことができます!
これにより、画像に基づくキャプション生成や、視覚質問応答(VQA)など幅広いタスクに対応することができるようになりました。
VLMにおけるCLIPの役割
現在主流となっているVLMは、その多くが視覚エンコーダとLLM(Large Language Models)を組み合わせたものになっています。人間で例えるならば、目(視覚エンコーダ)から得た情報を脳(LLM)で処理するような構造になっています。
多くのVLMでは、この目の役割として、CLIPの視覚エンコーダが採用されています。
CLIPの視覚エンコーダは、画像情報を言語情報と同じ意味空間に埋め込むことができるため、画像と言語の統合に利用できます。
CLIPを用いた代表的なVLM
LLaVA (Large Language and Vision Assistant)
CLIPが用いられている代表的なVLMとしてLLaVAを紹介します!
LLaVAは、大規模言語モデル(LLM)と画像認識能力を統合したVLMです。具体的には、テキスト(言語)と画像(視覚)を組み合わせて理解し、応答することができます。
CLIPの視覚エンコーダはLLaVAの視覚エンコーダとして採用されており、画像に関する応答をLLMが生成する際、このCLIPが抽出した画像特徴ベクトルが画像情報の核となります。また、LLaVAではCLIPが変換した画像特徴ベクトルをLLMが理解できる形に変換するAdapterが配置されています。
VLMにおけるCLIPの強み
VLMにおけるCLIPの強みを3つにまとめてみました。
- 1つ目が、高品質な視覚特徴抽出です。CLIPの視覚エンコーダは、4億ペア(画像とキャプション)の大規模データセットに基づいて学習することで、汎化性能の高い視覚特徴を提供することが可能です。
- 2つ目が、埋め込み空間の汎用性です。CLIPの画像とテキストを統合する埋め込み空間は、LLMに豊富な画像特徴を伝達します。
- そして3つ目が、ゼロショット適応力です。 CLIPのゼロショット性能の高さにより、LLaVAは特定のタスクに対しても追加データを学習すること無く、対応できます。
4.まとめ
今回は、CLIPが使われているマルチモーダルな最新モデルについて紹介しました。
記事を簡単にまとめます!
- CLIP (Contrastive Language-Image Pre-training) :
CLIPは画像とテキストを統合するマルチモーダルAIモデルで、視覚エンコーダ(画像→特徴ベクトル)とテキストエンコーダ(テキスト→特徴ベクトル)で構成されています。
- 画像生成モデルとCLIP:
画像生成モデルには、CLIPのテキストエンコーダがよく利用されており、ユーザーが入力したテキストプロンプトを特徴ベクトルに変換し、それに基づいて画像を生成します。また、CLIPは生成後の画像がテキストプロンプトにどれだけ一致しているかを評価する役割も果たします。
- CLIPとVLM(Vision-Language Models):
VLMでは、CLIPの画像エンコーダがよく利用されており、視覚情報をテキスト情報と同じ意味空間に埋め込むことで、画像と言語の統合的な理解を可能にします。この機能は、画像に基づくキャプション生成や視覚質問応答(VQA)など、テキストと画像を同時に扱うタスクに役立ちます。
これからも最新のAIモデルに使われている技術などを紹介していくのでぜひ御覧ください!
参考文献
Ramesh, Aditya, et al. “Hierarchical text-conditional image generation with clip latents.” arXiv preprint arXiv:2204.06125 1.2 (2022): 3.
菅沼雅徳. 画像認識の基礎. オーム社, 2024.









