


近年何かと注目されている人工知能(AI)ですが、AIの応用先の例として自然言語処理があります。人間と他の生物との顕著な違いは自然言語を使うかどうかという点であり、人間の知能に大きく影響を与えていると言われています。そのため、AIの研究で今最も注目されているといっても過言ではありません。
また、自然言語処理のAI技術を応用したChat-GPTの出現など、汎用言語モデルが出現して私たちの生活に影響を与えています。よって、今回はAIを用いた自然言語処理について解説していきます。
Contents
0. 自然言語処理の基本的知識
自然言語とは会話や文章などで日常的に扱っている言葉、言語です。自然言語を扱う上で考慮すべき特徴は
- 扱うデータは文章であり、可変長のデータであること
- 画像や音声同様ベクトルとして数値化する必要があること
- 言語には曖昧な部分が多くあり、曖昧な部分を扱うことが非常に難しいこと
- 文章は順序が大切な時系列データとして扱われること
です。このイメージがあると自然言語処理の仕組みを理解しやすいと思います。
1. ベクトル化の手法
先ほど説明したようにAIで言語を扱うために、言語をベクトルに変換し数値化する必要があります。言語は文章や単語、文字などある程度の塊に分けて扱いますが、多くの場合単語を基本的な単位として使用します。この基本単位をトークンといい、基本的にトークンは単語のことを指します。
文章をベクトルとして表現する手法はいくつかあるので、見ていきましょう。
1.1 Bag-Of-Words(BOW)
ベクトルを用いて文章の解析を行う最も基本的な手法がBag-Of-Words(BOW)と呼ばれる手法です。BOWは文章で出てきた単語に出現頻度ごとに数値を与えます。これはつまり、以下の表のようにそれぞれの単語が文章に出現するか否かをone-hotの形でベクトル化するということです。
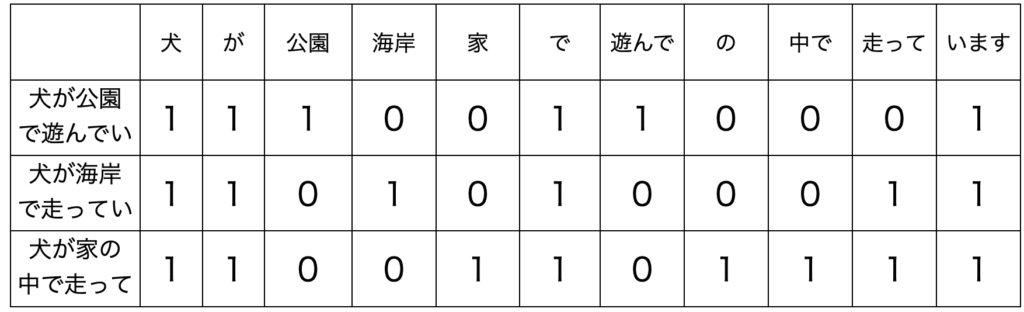
問題点として、BOWでは出現頻度で単語同士を関連付けるため、前後の文脈を考慮することはできません(例えば、「リンゴの次にミカンを食べる」という文章と「ミカンの次にリンゴを食べる」という文章の区別ができません)。また、文章が長い場合にはベクトルサイズが非常に大きくなってしまいます。
1.2 Word Embedding
BOWでは文章の出現頻度に注目しており、前後の並びを考慮することができませんでした。また、BOWでは文同士の比較はできても単語ごとの比較はできません。そこで考えつく一つの解決法は単語それぞれに別々の数字を割り当てる、という方法です。
例えば「吾輩は猫である」という文章なら「吾輩」に1という番号を、「猫」に2の番号を割り当てる、といった具合です。これなら前後の並びを考慮できます。しかし、この方法にも単語間の関係は全く表せないという問題があります。番号が近い=単語として意味が近い、というわけではないのです。
そこで「単語の意味はその周囲の単語から形成される」という分布意味仮説に基づき、単語自体を低次元のベクトルで表現することにしたのがWord Embeddingという手法です。なお、単語に対応づけられたベクトルを分散表現と言います。
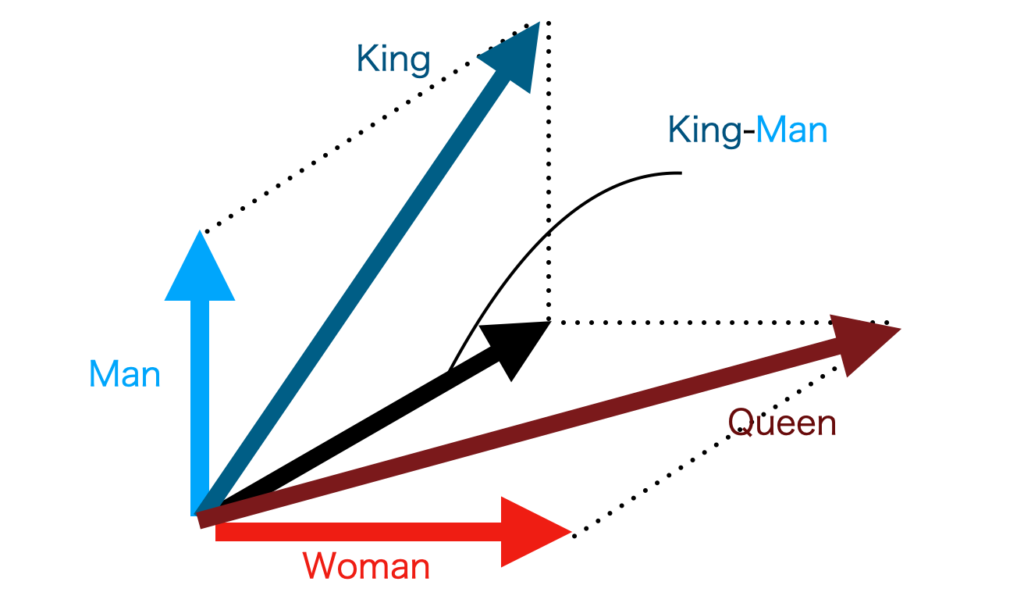
Word Embeddingでは、単語とベクトルの関係はニューラルネットワークを用いて学習することで取得します。また、Word Embeddingにより得られる分散表現の特性として加法構成性が挙げられます。例えばkingを表すベクトルVec(King)からVec(Man)を引いてVec(Woman)を足すとVec(Queen)となります。このように、分散表現の加減算と意味的な加減算が一致するような性質を加法構成性といいます。
1.3. 潜在的意味インデキシング(LSI)
他に潜在的意味インデキシング(LSI)という手法があり、これはBag-Of-Words(BOW)が元になっていますが、単語をベクトル化する手法ではなく、単語や文章に存在する潜在的な意味を取り出す手法です。LSIを使えば似た意味の単語や文章でグループ分けしたりでき、検索の精度を向上できます。
LSIではまず、BOWと同様に文章内における各単語の頻度でベクトル化を行います。この結果、行が単語を表し、列が文章を表す単語-文章行列ができます。その後、特異値分解を用いて次元削減を行います。これにより、意味的に繋がりがあるベクトルを潜在空間上で近い位置で表すことができ、単語同士を関連付けることができます。
しかし、実際の意味で考慮されているわけではなく、出現頻度で関連づけられているため、完全には意味的な関係を表しているとは言えません。文脈が考慮されているわけではなく、あくまで出現頻度による関係を表します。ただ、意味的なつながりが出現頻度から見出されることがあるので結果として意味的に近いものをベクトル空間上で近づけていると考えられます。また、特異値分解はデータセットが大規模になったときに計算コストがかかりすぎるという問題があります。
2. N-gram
ニューラルネットが使われる前に提案されていた手法の一つにN-gramがあります。N-gram もできるだけ文脈を考慮できるように直前の単語の情報を含める仕組みになっており、N-gramの”N”は直前の何単語を考慮するかを表しています。

N-gramは上のように単語のベクトルをそれぞれ前後の単語を含めた形で表します。このようにベクトルで表すことで、テキストの中でどのような単語や文字が頻出しているか、どのような組み合わせが現れるかを把握するのに役立ちます。2, 3 – gram などは文章の局所的な意味やフレーズを捉えることができます。Nが大きいほど考慮する大きさが増えますが、計算量も膨大になります。
3. Word2Vec
Word Embeddingについて先述しましたが、Word Embeddingを行う代表的な手法がWord2Vecです。ニューラルネットから構成され、簡単な構造で単語の分散表現を計算することができます。
Word2Vecではこのあと説明するContinuous Bag-of-Words (CBOW)とSkip-gramという二つのモデルが提案されています。以下の図[1]では左側がCBOW、右側がSkip-gramです。これらのモデルについて解説していきます。
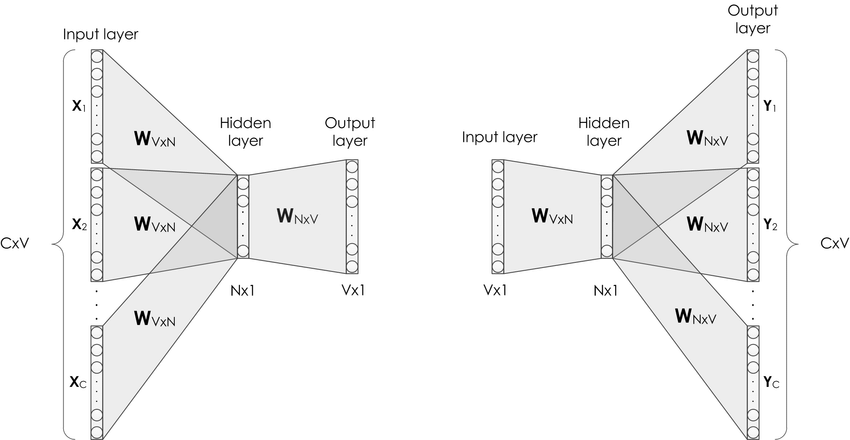
3.1 Continuous Bag-of-Words (CBOW)
CBOWはある文章が与えられたとき、どの文章中のi番目に位置する単語を、周囲の単語から予測するモデルです。考慮する周囲の単語の範囲はウィンドウサイズと呼ばれるパラメータです。CBOWは、主に単語をベクトルに変換する埋め込み層、予測する単語をベクトルに変換する埋め込み層の二つの層で構成されます。
計算式としては、単語のリスト \(H_i\) を入力として目標単語 \(\boldsymbol{y}_j\)の出現確率を求め、最も確率が高いものが予測単語となります。 その過程では、まず考慮する周囲の単語もベクトル化し、それらを平均します。 さらに、その平均値と単語の内積を計算することで、出現しやすさをスコアとして出します。 内積は数学的には類似度を計算していることに相当します。 最終的に、スコアをSoftmax関数で確率として表現し、 \(P\left(\boldsymbol{y}_j|H\right)=\frac{\exp{\left(\phi\left(H,\boldsymbol{y}_j\right)\right)}}{\sum \exp{\left(\phi\left(H,\boldsymbol{y}_j\right)\right)}}\) のようにモデル化できます。ここでφは平均との内積計算を表しています。
3.2 Skip-gram
一方、Skip-gramはCBOWを逆にしたようなモデルで、文中のある単語が与えられたとき、その周りの文脈に出現する単語を予測します。計算方法やモデル構造における考え方はCBOWとほとんど変わりません。
入力が中心の単語を表す \(\boldsymbol{x}_i\) になります。 \(\boldsymbol{x}_i\) は、先ほどの単語のリスト \(H\) の一部の1つの単語です。同じように周囲の単語の出現確率 \(\boldsymbol{y}_j\) を求めます。変わるところは説明したように入力のみです。出現する確率を表す式は \(P\left(\boldsymbol{y}_j|\boldsymbol{x}_i\right)=\frac{\exp{\left(\phi\left(\boldsymbol{x}_i,\boldsymbol{y}_j\right)\right)}}{\sum \exp{\left(\phi\left(\boldsymbol{x}_i,\boldsymbol{y}_j\right)\right)}}\)となります。
ネガティブサンプリング
上の数式で示したように CBOW と Skip-gram で中心の単語を予測したり周辺の単語を学習することができることがわかったと思います。数式の分母に注目すると、単語の数が大きい場合全ての単語に対して計算すると計算のコストが非常に多くなることがわかります。そのため実際に学習を行う場合は一部の単語のみを用いて学習します。その時、文脈に関係する単語は確率を高くし、全く関係ない単語では確率を低くするように学習する手法をネガティブサンプリングと言います。この手法はWord2Vec以外でも様々なモデルで利用されています。
Word2Vecの問題点
Word2Vecより周辺の単語から文脈を考慮した予測が可能になりました。しかし、完全ではなく問題点もあります。例えば、反義語や多義語を正確に扱うことができません。例えば
- 実験は( )した。
の場合、成功、失敗の両方が当てはまる可能性があります。また、“やばい“ などといった最近では多くの意味を持つ単語もあり、このような多義語も判断することが難しいという問題があります。
参考文献
- [1] https://www.researchgate.net/figure/Illustration-of-the-word2vec-models-a-CBOW-b-skip-gram-16-33_fig2_318507923
- 『深層学習による自然言語処理』講談社機械学習プロフェッショナルシリーズ 著作:坪井裕太, 海野裕也, 鈴木潤










