

今回は有名な自然言語処理モデルであるTransformer(Ashish et al., 2017, “Attention Is All You Need”)について、実装の仕方も含めて解説していきます。
Contents
Transfomerとは
Transformerは2017年にAshishらによって発表された有名な自然言語処理モデルです。最近話題になったChatGPTに用いられているモデルであるGPTにおいても、Transformerの技術は基礎となっています。Transformerは従来の自然言語処理モデルseq2seqにおける大域的な文脈(長期的な依存性)の考慮が難しい、勾配消失が生じるといった問題をクリアした上、大幅な並列化による学習速度の高速化も実現しました。その上で通常のリカレントニューラルネットワークを上回る予測精度を出し、自然言語処理の最先端を支えるモデルとなっています。
Transformerの仕組み
Transformer Blockについて
それではTransformerについて細かく見ていきましょう。まず、Transformerの全体構造は以下のようになっています。
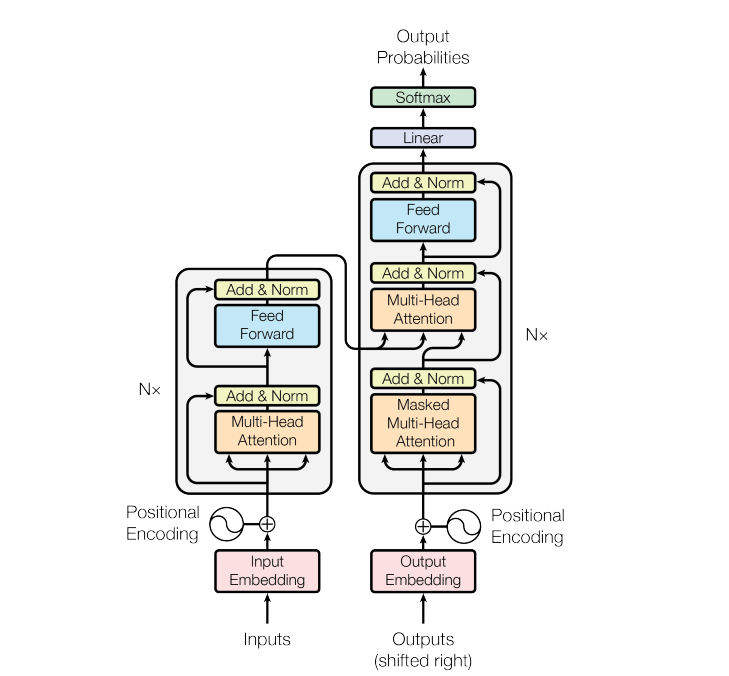
翻訳や自然言語処理などを行うモデルはエンコーダ(入力部)・デコーダ(出力部)構造になりますが、この図では左半分がエンコーディング部分、右半分がデコーディング部分にそれぞれなっています。エンコーダ部分の灰色の枠内がTransformerの本体と言ってよく、この部分をTransformer Blockと呼びます。
Transformer Block内においては、従来の手法で用いられていた畳み込みニューラルネットワークやリカレントニューラルネットワークを完全に排除し、Attention機構という仕組みに基づいて予測を行っています。Attentionは日本語で「注意」という意味であり、Attention機構ではその名の通り文章などのシーケンスのどこに注目すべきかを計算します。よって、この機構により大域的な文脈の考慮が可能となっています。
拡大すると以下のようになっています。
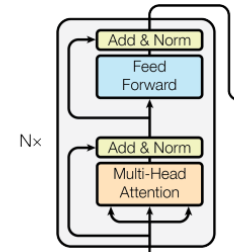
Multi-Head Attentionの部分がAttention機構に相当します。さらにMulti-Head Attentionの内部構造は以下の図3右のようになっています。
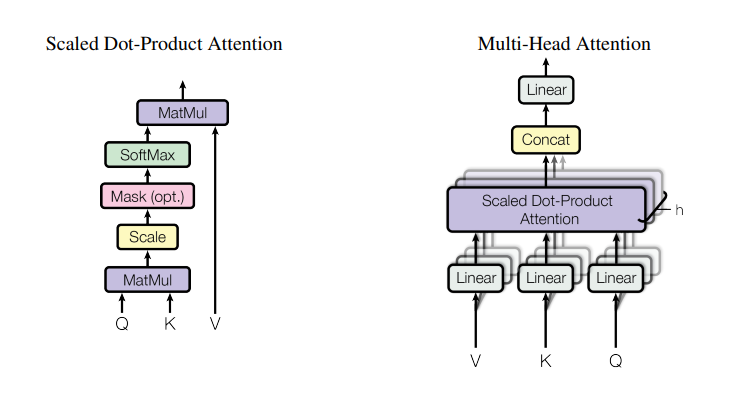
Scaled Dot-Product Attentionとその前のLinear層を並列に複数用いて表現能力を高くする構造になっています。Scaled Dot-Product Attention内部では、Attention機構のより詳細な計算処理が行われており、この部分が真の本体と言えます。
Scaled Dot-Product Attention、Multi-Head Attentionそれぞれについてより詳しく見てみましょう。
Scaled Dot-Product Attentionについて
Scaled Dot-Product Attentionは図3左のような構造をしています。この部分はAttention機構のより詳細な計算処理を担っており、文章などのシーケンスのどこに注目すべきかを特徴量として計算します。では、Scaled Dot-Product Attentionはどうやってどこに注目すべきかを計算しているのかについて説明していきましょう。
図3左のように、Scaled Dot-Product Attentionはまず入力としてQuery(Q)、Key(K)、Value(V)を受け取ります。Queryは簡単に説明すると、入力シーケンスにおいて検索したいもの(文章における一単語など)を表します。また、KeyとValueは探索の元となるデータ(文章など)を表します。KeyとValueはペアであり、Valueが実際の値だとするとKeyはそれに紐づいているラベルみたいなものです。重要な点として、単語はそのままだと計算に使えないため、ベクトル化して用います。
ここで、Keyの次元はdk、Valueの次元はdvとしておきます。
処理としてはまず、QueryとKeyのドット積を計算し、その各要素を√dkで割ります。このQueryとKeyから計算される重み行列をAttention行列と呼びます。次に、Attention行列をSoftmax関数で0~1の範囲の値にスケーリングした後、最後にValueとのドット積を計算します。出力はValueの重み付き和となり、この出力はAttention値と呼ばれます。なお、実際には単語ごとのQuery、Key、Valueをそれぞれ行列Q、K、Vにまとめて計算します。
この処理を数式で表すと
となります。
文章だけではよくわからない処理だったと思うので、具体例を見てみましょう。
例えば、「これはペンです。」という文章を英語に翻訳する場合を考えてみます。翻訳などの場合はKeyとValueはどちらも同じ値を用いることが多いので、ここではKeyとValueは同じ値と見なしましょう。ここで、Queryとして「pen」という英単語を選択したとします。Queryと全てのKeyとのドット積を取るわけですが、ドット積を取ると、QueryとそれぞれのKeyとの類似度が算出されます。Queryに意味が近いKeyほど高い値が出る、といった具合です。これにより、QueryとKeyの類似度を表す行列ができます。仮に文がもっと長いときでも同様にQueryとKeyの全てのドット積を取るため、長期依存性の考慮に悩む必要がありません。
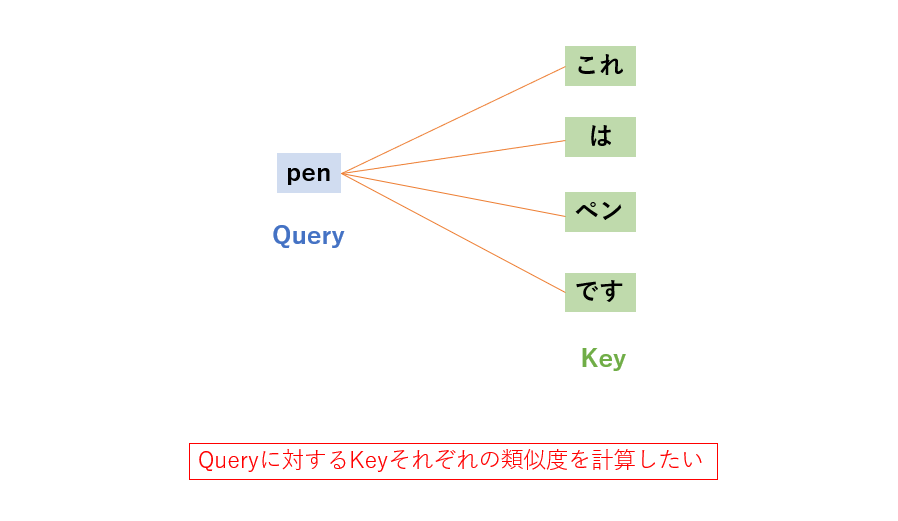
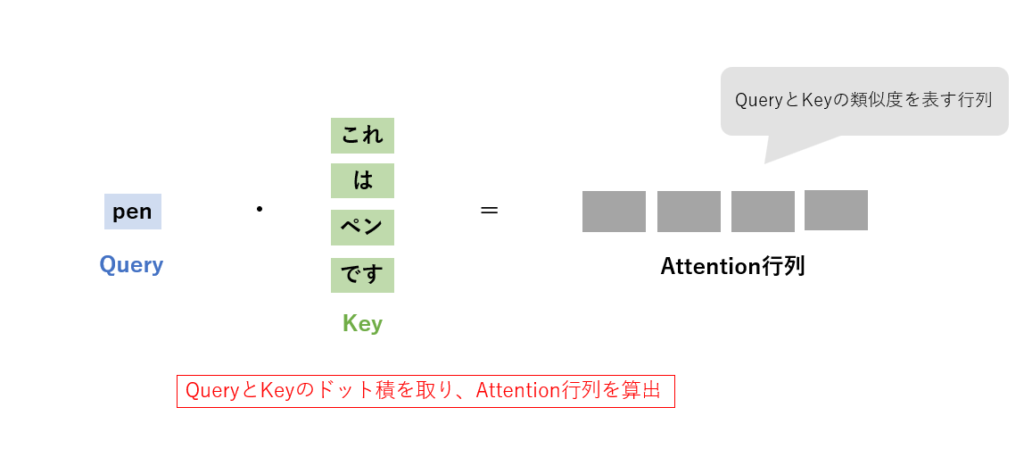
このようにして、Attention行列は「pen」という英語には「ペン」という日本語が類似している、というようなことを表すようになります。上の例では、「pen」という英単語の和訳である「ペン」という単語の類似度が最も高い値となります。
最後にスケーリングをしてからValueとのドット積を計算し、出力値はAttention行列によって重み付けされたValueの和となります。
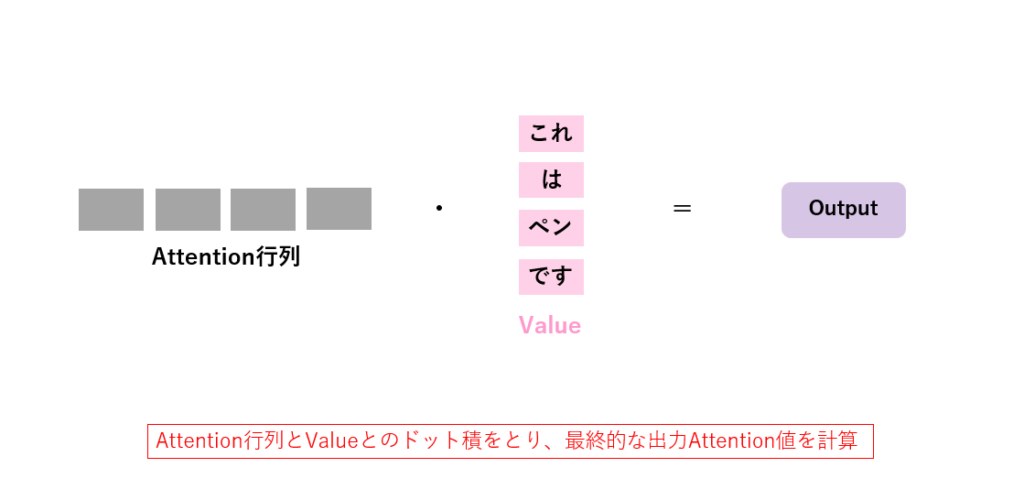
ここで、Valueが特徴量の類似度によって重みづけされるのはわかっても、その和を取るというのがピンとこない人が多いかもしれません。これはCNNの畳み込み演算をイメージしてもらうとわかりやすいでしょう。畳み込みでは、画像の全体にわたってカーネルという重み行列をかけ、その値を足したものを新たな特徴量マップとして出力するという処理を行っていました。
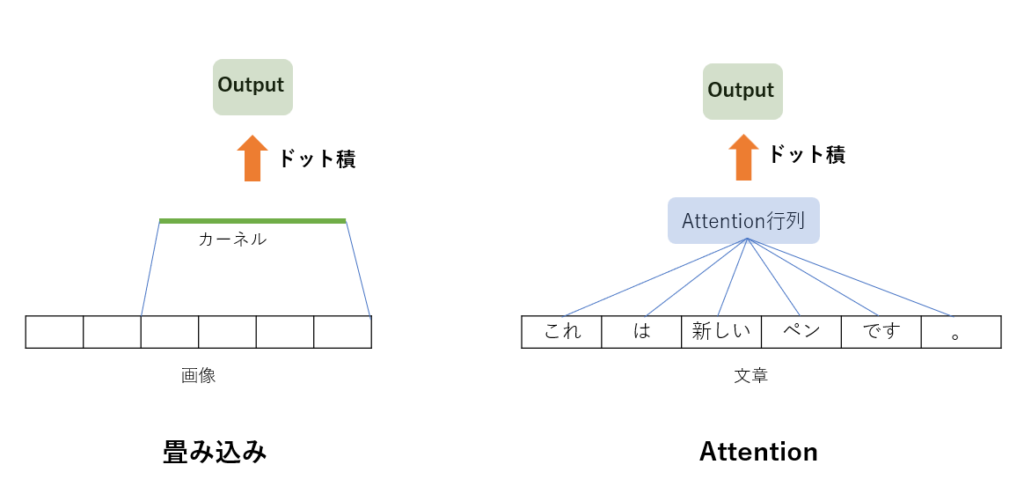
これに対し、Attention構造ではValue(文章)にAttention行列という重み行列をかけ、その値を足し合わせたものを出力とするという処理を行っており、両者は似ていることがわかります。畳み込みと同様に、Attention行列というフィルタを掛けることでValueから特徴量を抽出できるというわけです。
では、Scaled-dot product Attentionを簡単に実装してみましょう。まず、Attention行列をヒートマップで可視化するための関数を作成しておきます。試しにAttention行列が10×10の対角行列の場合を可視化してみましょう。
対角成分の値が高いということが一目でわかります。では、簡単なScaled-dot product Attentionを実装し、Attention行列を計算して可視化してみましょう。DotProductAttention関数内で、すでに説明した通りの処理を行っている点に注意してください。今回はQuery, Key, Valueとも適当にランダムな行列を設定しています。
簡単な例ではありますが、Attention行列の可視化、出力の表示ができました。QueryとKeyの類似度が可視化されています。
ここまでがAttention機構の核となるScaled Dot-Product Attention処理ですが、まとめると
- Attentionへの入力はQuery、Key、Valueである
- QueryとKeyのドット積を取ることで、類似度を表すAttention行列を作成する
- 出力はAttention行列によって重み付けされたValueの線形和である
ということになります。
これまで見てきたような、QueryとKey, Valueとで別々の文章を用いるAttention機構はSource Target Attentionと呼びます。
なお、今回の説明では翻訳の場合を考えましたが、この後の実装においては学習データに基づいて意味の通る文章を正しく出力できるかを試します。そのような場合、別々の文章同士ではなく、一文内において、ある単語と他の単語との類似度を計算するSelf-Attentionという構造を用います。Source Target Attentionと異なり、Self-AttentionにおいてはQueryも同じ文から作成します。そのため、Query自身との類似度を計算しないように実装では工夫が必要です。これについては後で実装の際に触れます。
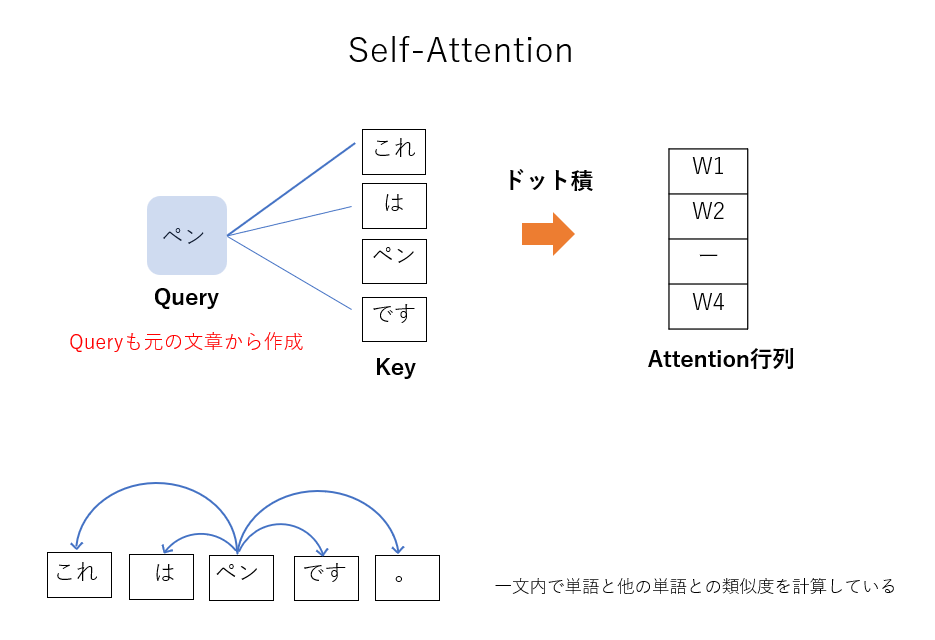
もう一つ付け加えておく重要なことがあります。ここまで見てきたScaled Dot-Product Attention処理そのものには、学習すべきパラメータが出てきませんでしたが、これでは多様な表現能力を獲得できません。そこで、実際にはQuery, Key, Valueを入力する前にそれぞれ別々の線形層に通します。この線形層のパラメータを学習することで、多様な表現能力を持つAttention機構ができます。
Multi-Head Attentionについて
次に、Multi-Head Attentionについてもより詳しく見てみましょう。Multi-Head Attentionの構造は以下の図右のようになっており、Scaled Dot-Product Attentionが並列されているのでした。
これを見ると、Query, Key, Valueはいずれもh個のScaled Dot-Product Attention全てに並列に入力されていることがわかります。こうすることで、様々な意味をもつ文章や単語に対して単一の意味に限定せず、様々な注意表現を同時に獲得することができます。一つのScaled Dot-Product Attentionでは文章のもつ様々な意味が平均化されてしまいますが、複数のScaled Dot-Product Attentionを一つの文章に同時に適用することで多用な意味を考慮することができるようになります。
Transformerの論文中ではScaled Dot-Product Attentionを8つ並列して用いており、Query, Key, Valueはそれぞれ入力する前にLinear層を用いて次元を削減することで並列化に伴う計算量の増加を緩和しています。また、8つのヘッド出力は再びConcatで一つに統一され、行列Woにより線形変換を行うことで、最終的な出力を得ます。
これを数式で表すと
のようになります。
ちなみに、Multi-Head Attentionの実装例を簡単に示すと以下のようになります。
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size, num_heads):
super(MultiHeadAttention, self).__init__()
self.emb_size = emb_size
self.num_heads = num_heads
self.keys = nn.Linear(emb_size, emb_size)
self.queries = nn.Linear(emb_size, emb_size)
self.values = nn.Linear(emb_size, emb_size)
self.unify_heads = nn.Linear(emb_size, emb_size)
def forward(self, x):
b, t, e = x.size()
h = self.num_heads
assert e == self.emb_size, f'Expected input embedding size {self.emb_size}, but got {e}'
keys = self.keys(x).view(b, t, h, e // h)
queries = self.queries(x).view(b, t, h, e // h)
values = self.values(x).view(b, t, h, e // h)
keys = rearrange(keys, 'b t h d -> b h t d')
queries = rearrange(queries, 'b t h d -> b h t d')
values = rearrange(values, 'b t h d -> b h t d')
#keyとqueryの積
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys)
attention = torch.softmax(energy / (e ** (1 / 2)), dim=-1)
#attentionでvalueを重みづけし、足し合わせる
out = torch.einsum('bhal, bhlv -> bhav', attention, values)
out = rearrange(out, 'b h t d -> b t (h d)')
return self.unify_heads(out) #ヘッドの統合処理Transformerの実装
では、Transformerの仕組みがわかったところで実装してみましょう。今回実装するのはかなり簡単なモデルにとどめ、Transformerによる予測も単純な短い文を想定します。また、翻訳タスクではなく自然な文章を作るという簡単なタスクを行うので、エンコーダ部分のみでデコーダ部分は作成しません。
学習に用いるテキストデータとしてはnanogpt-lectureからhttps://github.com/karpathy/ng-video-lecture/blob/master/input.txtを用います。テキストデータの文字数は1115393と莫大ですが、今回はかなりデータを小さくして学習に用います。
文章のままでは計算できないので、文章を適当な単位に分割し、数値データに変換しましょう。この作業をトークン化(トークナイズ)と言います。また、分割によって得られた文の構成要素をトークンと呼びます。単語単位や文字単位で分割することが多いですが、今回は単語単位で分割します。
ここでTrasformerのモデル図を見返してみるとEmbeddingという層がありますが、ここでは単語の埋め込みという処理を行います。埋め込みとは単語をベクトルとして数値化する処理のことで、このベクトル化された表現を分散表現と呼びます。トークン化した後は、埋め込みによってベクトルに変換する必要があります。この埋め込み部分は後でモデル中に含めます。
次に、Transformerの中枢であるMulti-Head Attention部分の実装に移りましょう。まずはMulti-Head Attentionを構成するScaled Dot-Product Attentionを実装します。
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embd, head_size, bias=False)
self.query = nn.Linear(n_embd, head_size, bias=False)
self.value = nn.Linear(n_embd, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
def forward(self, x):
B,T,C = x.shape
k = self.key(x) # (B,T,hs)
q = self.query(x) # (B,T,hs)
v = self.value(x) # (B,T,hs)
attention_weight = q @ k.transpose(-2,-1) * k.shape[-1]**-0.5 #Attention行列
#Self Attentionでは行列の一部のみを取り出すことで、
#トークンが自分自身との関連性を計算するのを防ぐ
attention_weight = attention_weight.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
attention_weight = F.softmax(wei, dim=-1)
out = attention_weight @ v
return outKey, Query, Valueを計算してAttention行列とValueのドット積をとるという、ほぼ論文通りの処理を行っています。なお、今回は翻訳ではなく意味の通る文章を正しく出力したいので、一つの入力からKey, Query, Valueを作成するSelf-Attention構造にしています。説明した通り、Self-Attentionでは別々の文章同士ではなく、一文内において、ある単語と他の単語との類似度を計算します。そのため、Attention行列の一部のみを取り出し、トークンが自分自身との関連性を計算しないようにするという処理を行っている点に注意してください。
続いて、Multi-Head Attentionです。h個のScaled Dot-Product Attention出力を結合し、線形層に通すだけです。
class MultiHeadAttention(nn.Module):
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)]) #ヘッド数分並列
self.proj = nn.Linear(head_size * num_heads, n_embd)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1) #ヘッド結合
out = self.proj(out)
return outここまででAttention層の実装は完了です。続いて、Feed Forwardネットワークの実装に入ります。Transformerのモデル図において青い四角で示された箇所です。Feed Forwardネットワークはエンコーダ部分とデコーダ部分の両方にありますがいずれも全結合層二つとReLU関数一つからなっています。今回は簡単のため全結合層は一つにします。
class FeedFoward(nn.Module):
def __init__(self, n_embd):
super().__init__()
self.fc = nn.Linear(n_embd, n_embd), #今回は簡素なFeed Forwardを用いる
self.relu = nn.ReLU()
def forward(self, x):
x = self.fc(x)
x = self.relu(x)
return xこれらをまとめて、Transformerブロックとします。Transformerブロック中にはLayerNormによる正規化も含めます。
class Block(nn.Module):
def __init__(self, n_embd, n_head):
super().__init__()
head_size = n_embd // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedFoward(n_embd)
self.ln1 = nn.LayerNorm(n_embd) #正規化
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
return xよって、最終的なTransformerモデルは以下のようになります。
class TFModel(nn.Module):
def __init__(self, n_embd, char_size, block_size, n_head):
super().__init__()
self.token_embedding = nn.Embedding(char_size, n_embd) # 埋め込み
self.position_embedding = nn.Embedding(block_size, n_embd) # 位置埋め込み
self.block = Block(n_embd, n_head) # Transformer Block
self.linear = nn.Linear(n_embd , char_size)
def forward(self, idx, targets=None):
B, T= idx.shape
tok_emb = self.token_embedding(idx)
pos_emb = self.position_embedding(torch.arange(T))
x = tok_emb + pos_emb
x = self.block(x)
logits = self.linear(x)
if targets is None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss学習させてみる前に、100文字予測させてみます。この段階ではまだ自然な文章は作れないはずです。ついでに先ほど作ったAttention行列可視化プログラムで最初のヘッドのAttention行列だけ可視化してみます。
脈絡のない、意味のわからない文字列しか出力されません。Attention行列を見ても、どこに注目すべきかを把握できてないことがわかります。では、学習させてみてどれくらい変わるのか見てみましょう。
学習前に比べると比較的意味の通る文章が出力されたことがわかります。また、Attention行列を見るといくつか注目した点が可視化されており、きちんとAttention機構が機能していることがわかります。
まとめ
今回はTransformerについて解説し、その簡単な実装についてもまとめました。TransformerはTransformer Block内に主要な構造があり、Scaled Dot-Product AttentionによるAttention機構が重要な役目を果たします。今回扱った内容は非常に簡単なものであり、自然な文章を出力するだけのものであるため、興味がある方は日本語から英語への翻訳に挑戦してみたり、他の有名な言語モデルについて調べてみても面白いかもしれません。










