


こんにちは!
今回の記事は、以前紹介した自動プログラム生成手法の「VISPROG」を実際に実行してみるという内容になっています。「VISPROG」の詳細について知りたい方は、前回の記事をご覧ください!
この記事の最後に、Google Colab上で簡単に動かせるデモの紹介もしていますのでぜひご活用ください!
VISPROGとは?

一言でいうと、「自然言語(人間が普段使用する言語)による指示からタスクを解決するプログラムを自動生成する手法」です。具体的には、大規模言語モデルと呼ばれる自然言語に関する幅広いタスクを高性能に処理できるモデルを用いて、プログラムを自動生成します。
上の画像は画像編集タスクの例で、大規模言語モデルに「砂漠を草原に置き換えて」という指示文が入力されています。その結果、下のプログラムが自動生成され、実行結果が右上の画像です。指示通り、草原を走る車の画像に編集されています。このように「VISPROG」は、画像に関するタスクを解決するプログラムの生成が可能です。
では、大規模言語モデルを使ってどのようにプログラムの自動生成を行うのか簡単に説明していきます。より詳しい説明を知りたい方は、論文解説の記事を書いているので、そちらもチェックしてみてください!
VISPROGのプログラム自動生成手法
VISPROGのプログラム自動生成は、大規模言語モデルによって行われます。
プログラムが生成されるまでの流れとしては、
1.解決したいタスクの指示文を含んだプロンプトを作成する
2.大規模言語モデルにプロンプトを入力する
3.大規模言語モデルからプログラムが自動生成される
という3ステップになっています。
以降では、大規模言語モデルへ入力するプロンプトと、自動生成されるプログラムについて簡単に説明していきます。
大規模言語モデルへ入力するプロンプト
大規模言語モデルへのプロンプト(入力のこと)は、
「指示文+プログラムのペア」と「解決したいタスクの指示文」の2部で構成されています(図1)。
「指示文+プログラムのペア」は、指示文に対してどんなプログラムが求められるかを大規模言語モデルに示しています。
例示のあとに、実際に解決したいタスクに関する指示文を記述することで、指示文に応じた所望のプログラムが生成されるようになる仕組みです。
例示するプログラム等は人の手によって作成されたもので、タスクの種類によって例示部分の内容は変える必要があります。図1の例では、画像編集タスク用の「指示文+プログラムのペア」が使用されています。ただし、例示部分は用意されているものを使うため、プログラムの自動生成時に私達が用意するのは、実際に解決したいタスクに関する指示文のみになります。

大規模言語モデルが自動生成するプログラム
大規模言語モデルからは以下のようなプログラムが出力されます(図2)。
このプログラムは、各行で対応するモジュールを呼び出すプログラムになっています。
プログラムは1行目から順に実行されていき、各モジュール(Seg()、Replace()等)が引数に応じてセグメンテーションや画像の置換など、様々な処理を行っていきます。

次に、プログラムの各行がどのように動作しているのかを具体例を用いて説明していきます。
図3に、プログラムの実行結果を示しています。
左上にタスクの指示文と元画像があり、左下に実行後の編集された画像(Prediction)があります。この例での指示文は、「地面を雪のある地面に、クマをホッキョクグマに置き換えて」という画像編集タスクです。
図の右側には、プログラムの実行過程が示されています。
例えば、3行目の Select() モジュールでは、2行目で作成したセグメンテーション(領域分割)の中から ‘ground’ に該当する領域を選択するという処理が行われています。その後、4行目で Replace() モジュールによって、選択された ‘ground’ が ‘white snow’ に置き換えられています。
「VISPROG」が生成するプログラムは、入力された複雑なタスクを単純なタスクの組み合わせに分解し、適切なモジュールを呼び出し、順に実行していくことで、タスクを解決します。

タスクのデモ実行編
この章では、github(https://github.com/allenai/visprog)で公開されているデモンストレーションを実行してみたいと思います。対象となるタスクは全部で4種類あるのですが、今回はそのうちのVQA( Vision Question Answering)タスクを扱っていきたいと思います!
プログラムの自動生成に使用する大規模言語モデルは、元論文ではGPT-3でしたが、今回は、GPT-3.5-turboを使用しました!
VQA :Vision Question Answering(視覚質問応答)
このタスクは、画像に関する質問に回答する視覚的質問応答のタスクです!
今回は、デモ内で用意されていた1枚の画像に対して、3種類の質問をしてみました。
使用する画像は、「camel1.png」で、砂漠に女性とラクダが座っている画像になります。

では早速質問に移っていきましょう!
質問1: “How many people or animals are in the image?”(画像内の動物と人間の総数は?)
1つ目の質問は、画像内の動物と人の数の合計について聞いてみました。
細かい情報を必要としない、比較的簡単な質問だとは思いますがどのような回答が得られるのでしょうか。また、プログラムの実行結果も気になりますね!
生成されたプログラム以下のようになりました。
推論のステップを考察すると、1、2行目で、「人」と「動物」について検出をかけていますね。
3、4行目では、検出した「人」と「動物」の数をカウントし、5行目でそれらの数を足し合わせて最終的な回答としていることがわかります。
では、このプログラムの実行結果はどうなったのでしょうか。
BOX0=LOC(image=IMAGE,object='person')
BOX1=LOC(image=IMAGE,object='animal')
ANSWER0=COUNT(box=BOX0)
ANSWER1=COUNT(box=BOX1)
ANSWER2=EVAL(expr="{ANSWER0} + {ANSWER1}")
FINAL_RESULT=RESULT(var=ANSWER2)では、このプログラムの実行結果を確認してみましょう(図4)。
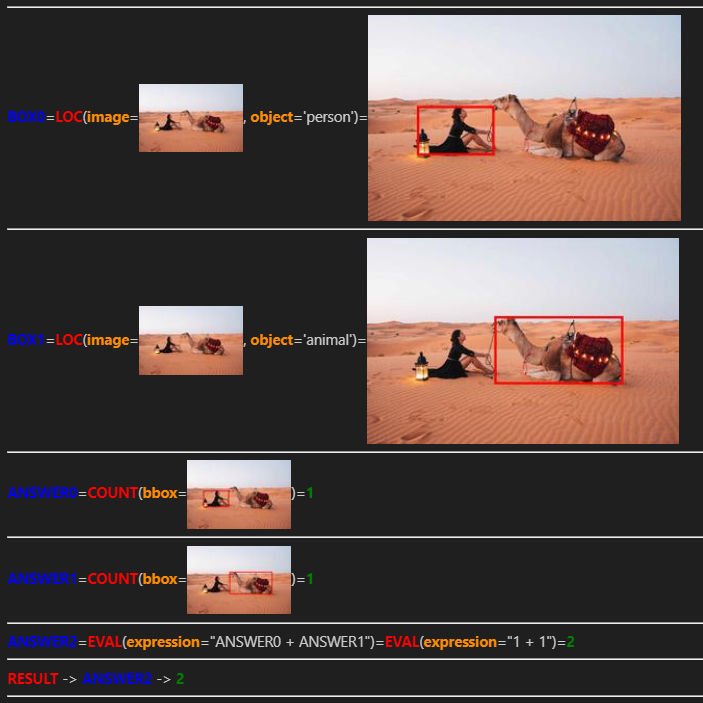
最終的な回答は「2」となっており、正しく回答できていることがわかりました!
「人」と「動物」をそれぞれ物体検出モジュールを使って検出し、その数をカウントしており、質問を回答するために、段階的なステップを踏んでいるのが賢いですよね。
VISPROG内で使用可能なモジュールには、画像に関する質問の回答を出力するVQAモデルも含まれています。ですが、質問によっては、今回のようにVQAモデルを呼び出さずに、確実な方法で回答を取得できる点がこの手法の強みだと考えられます。
質問2:”Localize the woman and tell me the color of her dress.”(女性の位置を特定し,着ているドレスの色を教えて)
2つ目の質問では、画像内の女性が着ているドレスの色が何色かを聞いてみました。
この質問は、1つ目の質問よりも詳細な情報を取得する必要があり、難易度が上がっていると思いますが正しく回答できるのでしょうか。
以下に、LLMによって生成されたプログラムを示します。
プログラムから推論のステップを考察すると、まず、1行目で女性の位置を特定し、2行目で女性をクロップした画像を作成します。その後、3行目でクロップ画像を用いて、VQAモデルに「ドレスの色は何色ですか?」と質問し、最終的な回答を得るという流れになっています。
BOX0=LOC(image=IMAGE,object='woman')
IMAGE0=CROP(image=IMAGE,box=BOX0)
ANSWER0=VQA(image=IMAGE0,question='What color is the dress?')
FINAL_RESULT=RESULT(var=ANSWER0)では、このプログラムの実行結果を確認してみましょう(図5)。
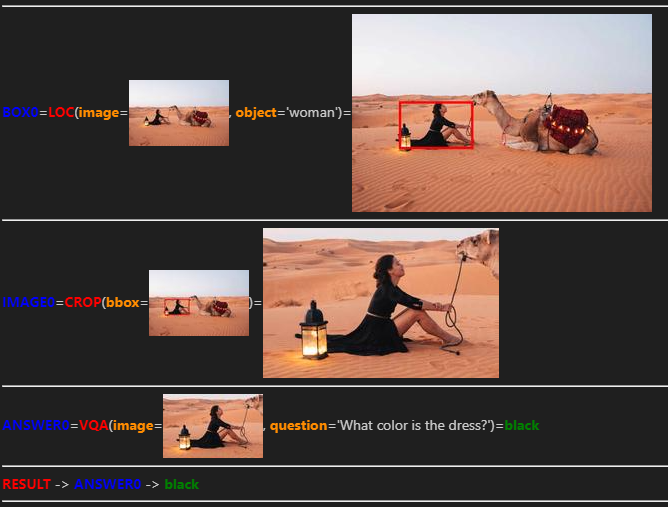
最終的な回答は”black”で、正しく回答できていました!
実行結果の図を見てもわかるように、質問に回答するために必要な要素に注目し、元画像から切り抜くことができています。これは、VQAモデルの回答の精度を向上させることにつながっています。
質問3:”Is there a sun in the sky?”(空に太陽はありますか?)
3つ目の質問として、空に太陽があるかどうかを聞いてみました。
この質問は存在しないものを対象としているので、今までの質問とは趣旨が異なりますね。
以下に生成されたプログラムを示します。
プログラムから推論のステップを考察すると、まず、1行目で「空」を検出し、2行目では、「空」のクロップ画像を作成しています。その後、作成したクロップ画像を用いて「太陽」を検出し、検出された「太陽」のboxの数をカウントしています。最終的な回答は、カウントが0より大きかったら’yes’、それ以外は’no’と選択するという流れになっています。
BOX0=LOC(image=IMAGE,object='sky')
IMAGE0=CROP(image=IMAGE,box=BOX0)
BOX1=LOC(image=IMAGE0,object='sun')
ANSWER0=COUNT(box=BOX1)
ANSWER1=EVAL(expr="'yes' if {ANSWER0} > 0 else 'no'")
FINAL_RESULT=RESULT(var=ANSWER1)では、実際にプログラムの実行結果を確認してみましょう(図6)。
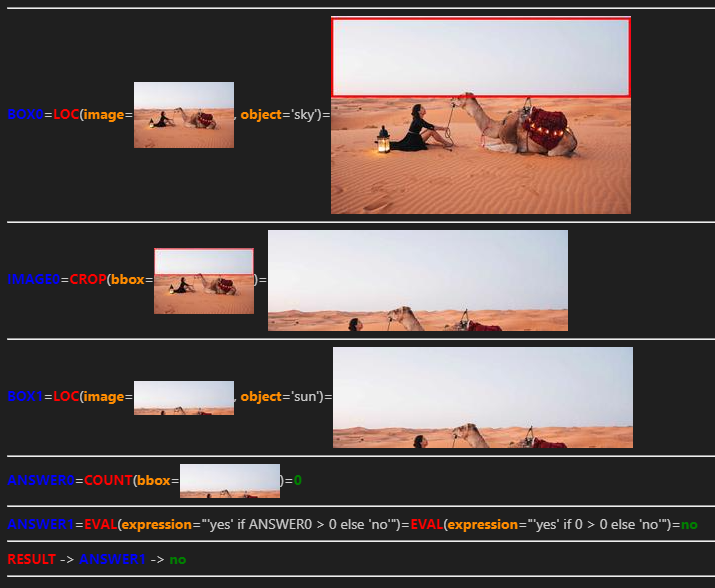
最終的な回答は”no”で、正しく回答できていました!
回答に必要な情報を得るため、「空」部分をきれいに切り抜き、「太陽」の有無を調べることができていて、人間のような論理的なステップを踏むことができていて、LLMはやはり優秀だなと感じました。
また、回答の精度が高いことも特徴的ですが、回答を出力するまでの過程も表示されるため、処理方法がわかりやすくてユーザに優しい仕組みになっているところも素晴らしいです。
論理的なステップを踏むことでの性能の違い
「VISPROG」には、VQAタスク専門のモジュールが登録されています。つまり、プログラムにするまでもなく、画像をそのモジュールに入力し、質問文を与えるだけでタスクを解決できるはずなんです。
しかし、「VISPROG」では、与えられた質問文から元画像の必要な部分のみをVQAモジュールに入力したり、VQAモジュールを呼び出さずに、物体検出モジュールのみを使用して質問の回答を得たりと、論理的なステップを踏みタスクを解決しています。
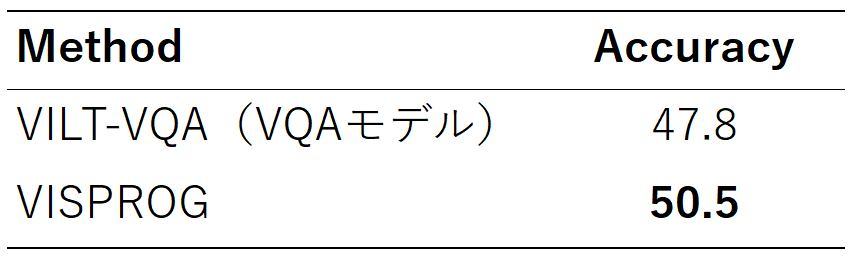
表1に、元画像をそのままVQAモデルに入力した場合と、本手法を使用した場合の回答の精度を示しています。この表からもわかるように、論理的なステップを踏むことで、VQAタスクの精度が向上していることがわかります!
まとめ
今回は、大規模言語モデルを使用してプログラム自動生成し、画像に関するタスクを解決する「VISPROG」のデモを動かしてみました。
Google Colabで簡単にデモを動かせるようにしているので、是非試してみてください!
参考
Gupta, Tanmay, and Aniruddha Kembhavi. “Visual programming: Compositional visual reasoning without training.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.(https://arxiv.org/pdf/2211.11559)










