機械学習の手法として大きく分けると教師あり学習、教師なし学習、強化学習があります。また、教師あり学習と教師なし学習との間には、その中間である半教師あり学習という手法も存在します。今回はこの半教師あり学習について解説し、いくつかの手法を紹介していきます。解説過程で教師あり学習や教師なし学習についても説明してますが、理解してる方は読み飛ばし、欲しいところだけ読んでいただければと思います。
Contents
1. 半教師あり学習とは
半教師あり学習とは何かについて説明します。その前に、まず教師あり学習、教師なし学習について簡単に説明したいと思います。
1.1 教師あり学習
多くの人が機械学習で最初に扱うのは教師あり学習だと思うので分かっているかもしれませんが一応説明します。機械学習はそもそもデータを与えてあげることで正しい予測モデルを作ることが目的です。教師あり学習は“正解“を導くためのモデルを作るわけですが、正解かどうかをデータとして与えてあげないと学習することができません。
具体的に説明すると、手書き数字の分類問題であれば、数字が書いてある画像と正解である数字のデータが必要です。他にも病気の診断をしてくれるモデルであれば症状やレントゲン画像などの患者のデータと実際の正解の診断結果が必要です。
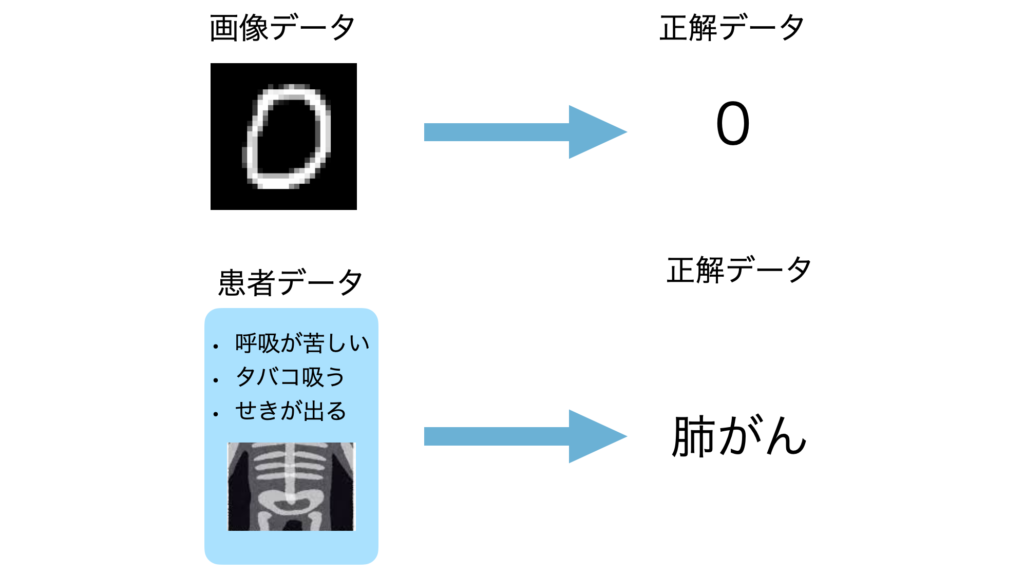
つまり正解ラベルを持たないデータをそのまま学習することはできません。そこでこれらの正解ラベルを持っていないデータに対して正解を与えるアノテーションという作業が必要でこれは人が行わなくてはなりません。データの数が多ければ多いほど大変になってしまいます。
1.2 教師なし学習
次に教師なし学習について説明します。教師なし学習はすべてのデータに正解データや正解ラベルが与えられていない状態で学習する手法です。データ同士の傾向を見つけたり、データをグループに分けるクラスタリング、影響の小さい変数を減らす次元削減などがタスクとしてあります。具体的な例をあげるとニュースなどを内容に基づいてカテゴリに分ける(クラスタリング)などがあります。教師あり学習と異なり、正解データを持つ必要がないためアノテーションの必要がありません。そのため学習をおこないやすいという特徴があります。一方、学習できるケースが教師あり学習に比べ少なく、学習がタスクの種類とデータに依存します。
1.3 半教師あり学習
では、半教師あり学習について説明していきます。半教師あり学習とは正解ラベルを持つデータとラベルが与えられていないデータ両方を含むデータセットに対してアノテーションをすることなく教師あり学習のようなことを行う手法です。教師なし学習の分類タスクの例では、正解が与えられていることで分類を正解ラベルをもとに行います。つまり、教師あり学習と教師なし学習の両方の性質を持つと言えます。
学習に使うことができるデータセットは膨大であり、その中には正解ラベルが与えられていないデータも含まれるデータセットがあります。教師あり学習で説明したようにアノテーションには非常にコストがかかるため、この半教師あり学習を用いることでアノテーションのコストを抑えつつ教師あり学習と同じくらいの性能を実現したいというのが半教師あり学習のモチベーションになります。
2. 半教師あり学習の手法
半教師あり学習は古くからある手法ですが、近年のAIブームで一層発展しました。今回は昔からある半教師あり学習の基本的な手法である自己訓練(Self-Training)、共同訓練(Co-Training)についてまず説明し、最後に近年の半教師あり学習を発展させるきっかけとなった対比学習(Contrastive learning)について説明します。
2.1 自己訓練(Self-Training)
最初に自己訓練(Self-training)について説明します。自己訓練は半教師あり学習でよく使われている手法です。以下に流れを図に表してみたので参考にしてください。まず、正解データがあるデータのみでモデルを学習します。これは通常の教師あり学習と同じですね。そして学習したモデルを用いて正解データがないデータの正解を予測します。すべての正解データが予測できたわけですが、このうち正解の可能性が高いデータのみを正解データを持たなかったデータに予測結果のラベルを当てて、正解データをもつデータとして扱います。正解の可能性が低かったデータはそのまま正解データなしのデータとします。その結果、新たに正解データをもつデータが追加されました。次にこの新たな正解データをもつデータを用いてモデルを学習します。そして、正解データを持たないデータを予測します。これを繰り返していくことで徐々に正解データが増えたデータを学習できるようになるという仕組みです。
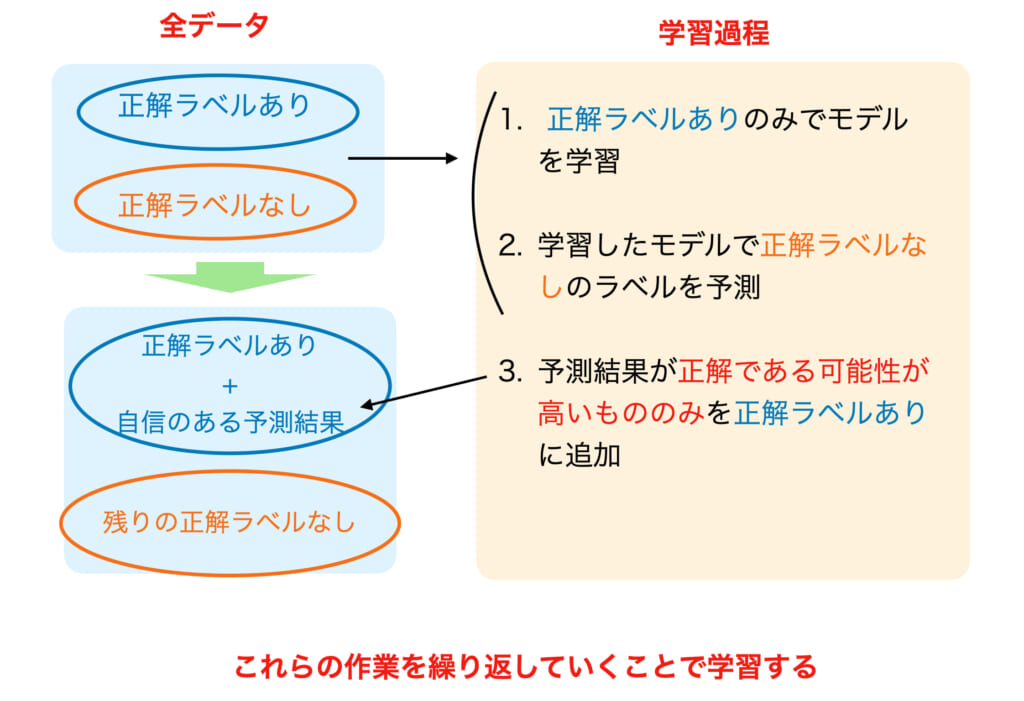
この仕組みから分かるように早い段階で正解ラベルとして与えられたデータが間違っていた場合精度があまり良くならない可能性があります。正解である可能性が高いもののみ次のデータに加えるという操作が重要です。
self-training は2000年よりも前から使われており、自然言語処理などで使われてきました。複数の意味を持つ単語を文脈によって意味を確定させるタスクや、文章から感情的か判断するタスクなどに応用されました。また、物体検知に使われたこともあります。
2.2 共同訓練(Co-Training)
次に共同訓練(Co-Training)について説明します。基本的な流れは先ほどの Self-Training と同じで、正解データをもつデータを学習し、持たないデータを予測、正解の可能性が高いものを正解データとして与え新たな正解データを持つデータをつくり、これを繰り返します。異なるのは、データセットを2つに分け、二つの分類器のモデルを互いのデータを用いて学習し、予測する点です。詳しく順番に説明していきます。
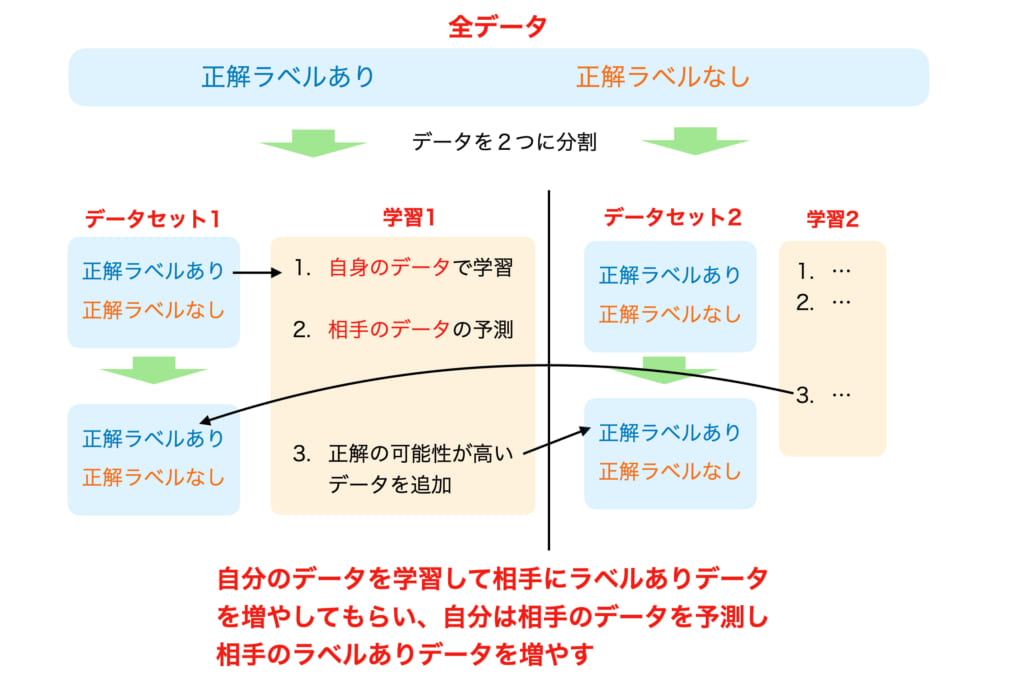
- データセットを2つに分ける
それぞれのデータセットは十分に学習できるデータ量があり、さらに条件付き独立であるとします。 - 2つのモデルをそれぞれ学習する
2つに分けたデータセットの正解データをもつデータをそれぞれ用いて2つのモデルを学習します。 - 予測して正解データを持つデータを作る
学習した2つのモデルを用いて学習した方とは違うもう一方のデータセットの正解データがないデータについて予測し、正解の可能性が高いものを正解データとして与えます。 - 繰り返し学習
再び、相手のモデルに教えてもらったデータを元のデータに加え学習します。その後、相手のデータを予測します。
学習を2つのモデルを使って行うため、最初に説明した Self-Training に比べ予測の誤りを減らしてくれる可能性が高くなります。また、上記の手法以外にも自身のデータと相手のデータ両方を予測して、一致する場合のみラベルを付与するという手法もあります。他にもモデルを3つにした Tri-training も提案されています。
2.3 対比学習(Contrastive Learning)
Constrastive Learning は半教師あり学習でも画像処理に用いられる手法です。最初に、基本的な仕組みについて説明します。Constrastive Learning は学習する際に、3つの画像を扱います。1つ目がアンカーと呼ばれる元々の画像です。2つ目が元々の画像であるアンカーと似た画像である正例です。そして3つ目が元々の画像と全く関係のない負例です。
学習の仕組みについてですが、アンカーと正例との類似度とアンカーと負例の類似度を求め、似ているものは近く、異なるものは遠くなるように学習することでエンコーダーを学習します。
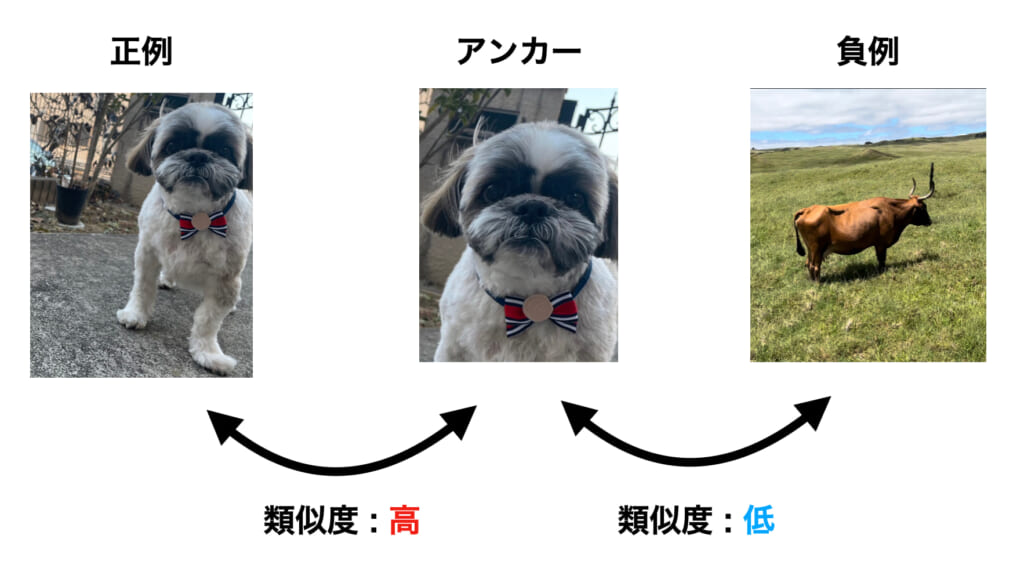
この類似度を測る方法としては自然言語モデルの類似度計算でも用いられるコサイン類似度などが用いられます。コサイン類似度はデータを表す2つのベクトルからコサインを求めることでそのデータ同士の距離を表そうというものです。損失関数はこのコサイン類似度を用いてアンカーと正例を近づけ、負例を遠くに表すような目的関数を採用します。様々な目的関数が提案されていますが、そのうちの1つである InfoNCE 損失は以下の式で表されます。
コサイン類似度をベクトル \(q\) と \(k^{±}\) の内積で表し、それぞれアンカーとの距離を求めています。 \(\tau\) は学習を制御するパラメータとなっています。 式を見るとわかると思いますが、類似度が近いと大きい値をとり(0に近づく)、類似度が低いと負の値をとり小さい値をとなる関数となっています。
対比学習で使われる正例はアンカーからデータオーギュメンテーション(Data Augmentation)によって作られることが多いです。オーギュメンテーションは画像に対して回転や色の変換、拡大・縮小など様々な変換でデータを水増しする手法ですが、扱うタスクによってどの変換を用いるかを選ぶ必要があります。先ほどの目的関数からもわかるように、Constrastive Learningでは負例をたくさん使います。この負例を保持する方法も様々な手法が提案されており、モデルの設計に重要な部分でもあります。
3. まとめ
今回は最近のAIの精度向上に大きく影響を与えている半教師あり学習について初期の手法であるSelf-Training、Co-Training、そしてContrastive Learningについて扱いました。基本的な仕組みのみ扱いましたが実装して性能を見てみるのも良いかと思います。ぜひ試してみてください。