


Grad-CAM++は、その名前が示す通りGrad-CAMを改良した手法です。Grad-CAMはCNNの構造に関わらず汎用的に使えるよう、クラスへの寄与を勾配を使って計算しています。一方、Grad-CAM++では、この勾配の計算をさらに細かく工夫することで、Grad-CAMの欠点であった「各ピクセルの重要度を均一に扱ってしまう点」を改善しています。これにより、各ピクセルごとのクラス判定への寄与をより正確に評価できるようになりました。
Contents
Grad-CAM++とは
Grad-CAM++(Gradient-weighted Class Activation Mapping++)とは、CNNが画像内のどこに注目して分類したかを可視化する「Grad-CAM」を改良した手法です。Grad-CAMでは、CNNの分類結果に対して各特徴マップの重要度を勾配を使って計算していましたが、その際に特徴マップの重要度は全ピクセルの勾配の平均によって決定するため、曖昧性が強いという課題がありました。具体的には、ピクセル範囲としては小さいがすごく重要な部分(勾配が大きい)がある場合でも、平均を取ってしまうため、特徴マップとしては重要ではないと判断されてしまう場合があるということです。そのため特徴マップ内の空間的な違いを無視してしまう手法になっていました。

Grad-CAM++ではこの点を改善し、各特徴マップ内の個々のピクセルごとに細かく重要度(重み)を計算する仕組みを導入しています。具体的には、勾配の情報をより詳細に解析(高次の微分を利用)することで、特徴マップ上でのピクセル単位の寄与を正確に捉えられるようになりました。この改良により、特徴マップにおける重要度をより厳密に求めることができるようになったのがGrad-CAM++です。
Grad-CAM++の利用結果
下記の画像は同じ画像に対してGrad-CAMとGrad-CAM++を適用した結果です。結果を見ると、Grad-CAM++はより正確に猫の部分がヒートマップ上で重要視されていることが分かります。このようにGrad-CAM++は複雑な計算をすることでより正確なヒートマップを実現しています。

Grad-CAM++の仕組み
Grad-CAM++がGrad-CAMと異なるのは、特徴マップの重要度の決定方法です。以下はGrad-CAM++の特徴マップの重要度を求める式です。

Grad-CAMと大きく異なる点は複数次元での微分を行うことです。これによる利点は、1次元の微分では一時的な増減はわかりますが、それが継続的なものかであるかがわかりません。一方、Grad-CAM++では、勾配そのものに加えて、勾配の変化量(二階・三階微分)も考慮することで、より精密に「本当に重要な領域」を見極めることができます。これにより、単に一時的に勾配が大きいだけの領域ではなく、継続的にモデルの出力に強く影響しているピクセルを特定することが可能になります。イメージとしては関数の増減表などに近いかもしれません。このようにしてGrad-CAM++は各ピクセルの重要度をより正確に把握し、特徴マップの重要度を決定しているわけです。
やってみよう
以下はGrad-CAM++のコードおよびその実験結果です。
import numpy as np
import tensorflow as tf
import cv2
import matplotlib.pyplot as plt
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions
# モデルと対象の層
base_model = ResNet50(weights='imagenet')
target_layer = base_model.get_layer("conv5_block3_out")
# Grad-CAM++ 実装
def grad_cam_plus_plus(model, image_path, class_index=None):
img = cv2.imread(image_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224, 224))
input_tensor = preprocess_input(np.expand_dims(img.astype(np.float32), axis=0))
grad_model = tf.keras.models.Model(
[model.inputs], [target_layer.output, model.output]
)
with tf.GradientTape() as tape:
conv_outputs, predictions = grad_model(input_tensor)
if class_index is None:
class_index = tf.argmax(predictions[0])
output = predictions[:, class_index]
grads = tape.gradient(output, conv_outputs)[0] # shape=(H, W, C)
conv_outputs = conv_outputs[0] # shape=(H, W, C)
# 二階勾配と三階勾配の近似
grads_squared = tf.square(grads)
grads_cubed = tf.pow(grads, 3)
global_sum = tf.reduce_sum(conv_outputs, axis=[0, 1])
alpha_numer = grads_squared
alpha_denom = 2 * grads_squared + global_sum * grads_cubed
alpha_denom = tf.where(alpha_denom != 0.0, alpha_denom, tf.ones_like(alpha_denom))
alphas = alpha_numer / (alpha_denom + 1e-7)
weights = tf.reduce_sum(alphas * tf.nn.relu(grads), axis=[0, 1]) # shape=(C,)
cam = tf.reduce_sum(weights * conv_outputs, axis=-1) # shape=(H,W)
cam = tf.nn.relu(cam)
cam = cam.numpy()
cam = (cam - cam.min()) / (cam.max() - cam.min() + 1e-8)
return cam, img
# ヒートマップと重ね合わせ画像を表示
def show_gradcam(image_path, cam_map):
original = cv2.imread(image_path)
original = cv2.cvtColor(original, cv2.COLOR_BGR2RGB)
heatmap = cv2.resize(cam_map, (original.shape[1], original.shape[0]))
heatmap = np.uint8(255 * heatmap)
heatmap_color = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
heatmap_color = cv2.cvtColor(heatmap_color, cv2.COLOR_BGR2RGB)
overlay = cv2.addWeighted(original, 0.6, heatmap_color, 0.4, 0)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.imshow(original)
plt.title("Original Image")
plt.axis("off")
plt.subplot(1, 2, 2)
plt.imshow(overlay)
plt.title("Grad-CAM++")
plt.axis("off")
plt.show()
# 使用例
if __name__ == "__main__":
image_path = "" # 画像のパス
cam_map, _ = grad_cam_plus_plus(base_model, image_path)
show_gradcam(image_path, cam_map)

画像の結果を見るとGrad-CAMに比べて正確に犬全体を捉えていることが分かります。これは、ピクセル単位により細かく注目したことで、重要な部分の見落としが少なくなったためだと考えられます。
Grad-CAMとGrad-CAM++のスコア比較
こちらはGrad-CAM++の論文である”Grad-CAM++: Improved Visual Explanations for
Deep Convolutional Networks”に掲載されているGrad-CAMとの性能比較の結果です。
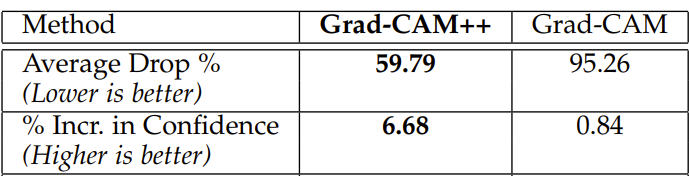
Average Drop
こちらはそれぞれの手法で重要と判断されたピクセルのみを画像解析モデルに与えた際に、画像全体を与えたときと比較してどれほど予測精度が低下するかを表したものです。Grad-CAMでは重要領域のみをモデルに入力した場合、およそ50%の精度低下が見られましたが、Grad-CAM++では約37%の低下にとどまりました。これは、Grad-CAM++の方がGrad-CAMに比べて約10%高い予測精度を維持できていることを示しており、より効果的な重要領域の抽出が行えていると考えられます。
Increase in Confidence
こちらは重要領域と判定された以外の部分を隠した画像を用いて分類を行った際にどれほど精度が上昇したかを示すものです。なぜ精度が上がるかというと画像の分類において重要ではない部分を取り除くため誤判定が減るからです。Grad-CAMとGrad-CAM++のスコアを比較すると、Grad-CAMは1%未満の精度向上であるのに対して、Grad-CAM++は6.7%の精度向上を達成しています。このことからGrad-CAM++のほうがGrad-CAMと比較して画像分類において重要ではない部分を判別できているということになります。
まとめ
今回はGrad-CAM++について紹介しました。Grad-CAM++は現在でも研究の最前線で使われることのある画期的な手法であるためぜひ試してみてください。










