


Contents
1.導入:CLIPとはなにか?
CLIP(Contrastive Language–Image Pretraining)は、2021年にOpenAIが発表した、テキストと画像という異なる次元(モダリティ)の情報を効果的に結びつける技術です。
画像と自然言語の特徴を共通する特徴空間に射影するエンコーダを学習することで、従来のアプローチでは困難だったタスクを高い精度で解決できる点が特徴です。
CLIPは、画像と言語を統合的に扱う分野に革命をもたらしました。この技術により、例えば、与えられた画像について質問に答える視覚質問応答(VQA)や、画像の内容を文章で説明する画像キャプション生成など、視覚と言語の統合が求められるタスクが大きく発展しました。
また、CLIPのユニークな点は、Web上の膨大な画像とテキストデータ(4億ペア)を利用して学習した汎用性の高いモデルであることです。この学習により、従来の特定タスク専用のモデルとは異なり、さまざまなタスクに柔軟に対応する能力を獲得しています。
次に、この技術の背景となる、画像と言語を扱う研究分野について詳しく説明します。
2.画像と自然言語(Vision and Language; V&L)
画像と自然言語(Vision and Language; V&L)とは、文字通り画像(視覚情報)と自然言語(言葉や文章)を統合的に利用するタスクを扱う研究分野です。
V&L分野の研究として有名なのは、与えられた画像に関する質問に答える画像質問応答(Visual Question Answering; VQA)や、与えられた画像の説明文を生成する画像キャプション生成(image captioning)などがあります。

V&L研究の難しさは、画像と言語の情報を適切に結びつけることです。
例えば、下の画像のように、イヌとネコが映っている画像に関して「Where is the dog located in the image?」という質問に答える場合を想定します。この質問に答えるためには、dog(言語)とイヌ(画像)の位置情報を結びつける必要があります。人間にとってはdog(言語)とイヌ(画像)を結びつけることは容易ですが、AIモデルにとっては非常に難しいことです。なぜなら、そもそも画像と言語という情報は全く異なる次元のデータであり、記述の形式も完全に異なるからです。
V&L研究のタスクを解決するためには、この画像表現と言語表現のズレをなくす必要があるため、それらを適切に結びつける(アラインメントする)ことが最大の課題でした。
アラインメントをわかりやすく説明すると、下の画像のように、画像と言語の共通する特徴空間に、元の情報を射影し、共通する情報が近くに存在していれば上手くアラインメントができているといえます。
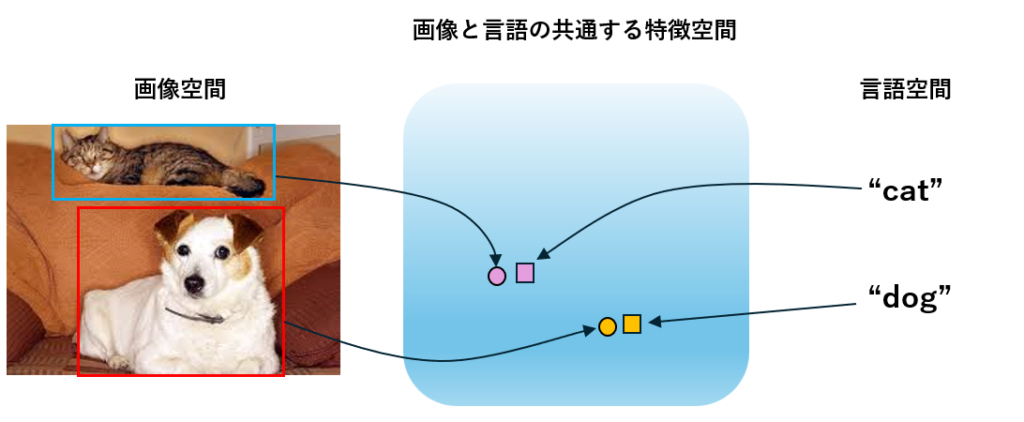
今回紹介するCLIPは、画像空間と言語空間から共通する特徴空間へと元情報を変換する変換器(エンコーダ)を高精度で効率的に学習する方法を提案し、V&L研究を大きく発展させました!
3.CLIPの手法を解説
CLIPが提案する学習方法を以下に示します。
CLIPは、Web上から収集した4億の画像・キャプションペアデータを用いて、画像エンコーダと言語エンコーダを対比学習によって最適化します。対比学習とは、類似しているデータを近づけ、異なるデータを遠ざけるように学習する方法です。
図の説明をすると、まず、言語エンコーダ(Text Encoder)と視覚エンコーダ(Image Encoder)が画像と言語を共通する特徴空間へと変換する変換器です。学習時には、言語エンコーダにキャプション Xi を、画像エンコーダに画像 Yi を入力します。そして、入力されたキャプションと画像はそれぞれ言語特徴ベクトル Tiと画像特徴ベクトル Ii と変換されます。具体的には、1枚目の画像とキャプションの特徴ベクトルがそれぞれ I1 とT1 のように表現されます。
その後、対応するペアの特徴表現の内積( Ii・Ti )が大きくなるよう、対応しないペアの内積(例:I1・T2,I3・T1等)が小さくなるように言語エンコーダと画像エンコーダの最適化を行います。
以上がCLIPの学習方法の簡単な説明になります。
最適化された各エンコーダは、優れた言語表現と画像表現が獲得されており、画像と言語に関する幅広いタスクに転用することができます。
次に、CLIPの強みについて説明していきます。
4.CLIPのゼロショット推論
CLIPは、対比学習によって、与えられた画像とテキストの内容が一致しているかどうかを高精度で予測する能力を持っています。その性能を評価する代表的なタスクの一つがゼロショット画像分類です。
ゼロショット(Zero-Shot)とは、AIモデルが事前に学習していないタスクやクラスに対して、追加の学習を行わずに対応する能力を指します。
従来の画像分類モデルでは、「犬」や「猫」などの特定のクラスについて、大量のデータで事前に訓練する必要がありました。しかし、CLIPはWeb上の膨大な画像とテキストのペアデータを活用して、あらゆる画像情報を言語情報と結びつける学習を行っています。
その結果、CLIPは事前に特定のクラスを学習させなくても、自然言語によるクラス名(例: “A photo of a dog”)を利用することで、柔軟かつ正確に分類を行うことが可能です。
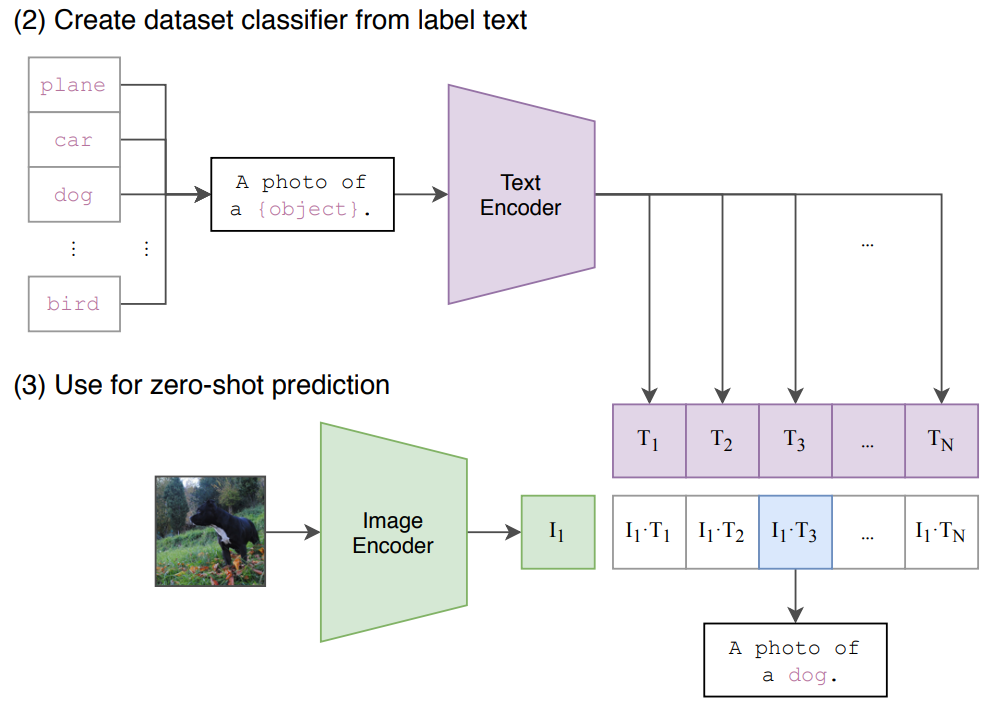
CLIPのゼロショット画像分類
CLIPは、画像とテキストを共通の特徴空間に射影するエンコーダを持っています。これにより、新しいカテゴリに対しても、以下の手順で対応することができます:
- モデルに、分類するクラスごとの説明文(例: “A photo of a dog”, “A photo of a cat”等)を入力。
- 入力画像と説明文の特徴ベクトルを比較し、最も類似度が高いクラスを選択。
このアプローチにより、事前に学習していないクラスでも柔軟に分類できるのがCLIPの特徴です。
CLIPによるゼロショット画像分類は、様々なデータセットで高い分類精度を示します。CLIPの文献では、27個のデータセット上での分類精度をResNet-50(CNN)と比較しており、16個のデータセットでCLIPが高い精度を達成したことを報告しています。
CLIPの最大の貢献は、Web上に存在する膨大な画像とキャプションを用いて、汎用性の高い画像エンコーダと言語エンコーダを構築可能であると示したことだと言われています。
従来の学習方法では、単語レベルでの入力など限られた情報を言語情報として与え、最適化することが多かったのに対し、CLIPでは、キャプションを学習に使用することにより幅広い概念の理解が可能になっています。
CLIPを実際に動かすコードの紹介
以下のコードでは、Hugging Faceのtransformersライブラリを使用して、事前学習済みのCLIPモデルをロードします。タスクとしては、「ゼロショット画像分類」であり、与えられた画像がどのラベルに当てはまるかを分類します。
import requests
from PIL import Image
from io import BytesIO
from transformers import CLIPProcessor, CLIPModel
# 画像URLを指定
image_url = "http://images.cocodataset.org/val2017/000000039769.jpg" # 猫の画像URL
# 画像データを取得
response = requests.get(image_url)
if response.status_code == 200:
image = Image.open(BytesIO(response.content)) # バイトデータをPillow Imageオブジェクトに変換
else:
raise Exception(f"Failed to fetch image: {response.status_code}")
# CLIPモデルとプロセッサのロード
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 分類ラベルを設定
labels = ["cat", "dog", "car", "tree"]
# 入力データを処理
inputs = processor(
text=labels,
images=image,
return_tensors="pt",
padding=True
)
# モデル推論
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # 類似度スコア
probs = logits_per_image.softmax(dim=1) # 確率に変換
# 各ラベルに対するスコアを表示
for label, score in zip(labels, probs[0].tolist()): # probs[0]で画像のスコアリストを取得
print(f"Label: {label}, Score: {score:.4f}")
# 最もスコアが高いラベルを表示
predicted_label = labels[probs.argmax()]
print(f"Predicted label: {predicted_label}")
結果は以下のようになりました。
画像とラベルの関連性が最も高い”cat”が予測結果として表示されました!
Label: cat, Score: 0.9747
Label: dog, Score: 0.0066
Label: car, Score: 0.0133
Label: tree, Score: 0.0053
Predicted label: catまた、分類ラベルに、”two cat”と”a cat”を入れてみた結果は以下のようになりました。
Label: two cat, Score: 0.9927
Label: a cat, Score: 0.0071
Label: dog, Score: 0.0001
Label: car, Score: 0.0001
Predicted label: two cat「two cat」が予測されました。完全に分類できていますね!
最後にキャプション形式のラベルを与えてみます。従来の学習方法では、単語レベルの分類しか実現できませんでしたが、キャプションを学習に使用しているCLIPは、文章レベルでの分類が可能です。
Label: two cat, Score: 0.3759
Label: two running cat , Score: 0.0621
Label: two cat on red blanket, Score: 0.3791
Label: two cat on blue blanket, Score: 0.1830
Predicted label: two cat on red blanket「two cat on red blanket」が最も適した文章であるとしっかりと分類することができています。
CLIPの分類性能の高さがわかりますね!
4億枚の画像とキャプションのペアデータを学習することで、画像内の詳しい情報も取得できています!
5.まとめ
今回は、CLIP(Contrastive Language–Image Pretraining)について説明しました。
以下に記事内容をまとめます。
- 汎用性の高いエンコーダの構築:
CLIPは、Web上の膨大な画像とキャプションデータを活用することで、幅広い概念を理解し、様々なタスクに転用可能な画像エンコーダと言語エンコーダを構築した。 - ゼロショット推論の実現:
新しいクラスでも事前学習なしで高い精度で分類を行えるゼロショット画像分類を実現し、画像と言語を結びつける能力を革新的に向上させた。
CLIPの登場により、視覚と言語を統合する分野での可能性が大きく広がりました!
参考文献
Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International conference on machine learning. PMLR, 2021. https://arxiv.org/pdf/2103.00020
菅沼雅徳. 画像認識の基礎. オーム社, 2024.









