

物体検出は、コンピュータビジョン分野における主要な研究テーマの一つで、様々なアルゴリズムが提案されています。今回はその中でも近年提案された代表的なアルゴリズムの一つであるFCOS(Fully Convolutional One-Stage Object Detection)について解説していきます。
Contents
FCOS(Fully Convolutional One-Stage Object Detection)とは
ここ数年、物体検出における有力なモデルとしてはYOLOやSSDなどのアンカーボックス(画像中における物体の領域を表すボックス)を用いた手法が主でした。しかし、これらのアンカーボックスを用いた手法にはボックスの縦横比の設定が必要、どうしてもデータの偏りが生じるなどの問題があります。
そこでアンカーボックスを用いない手法が議論されてきました。また、畳み込み層のみで構成される画像認識モデルの登場も受け、FCOSはTianらによって2019年に提案された、畳み込み層のみで構成されるアンカーフリーの物体検出モデルです(Tian et al., 2019, “FCOS: Fully Convolutional One-Stage Object Detection”)。
FCOSの構造
まず、FCOSのネットワークアーキテクチャは以下のようになっています。
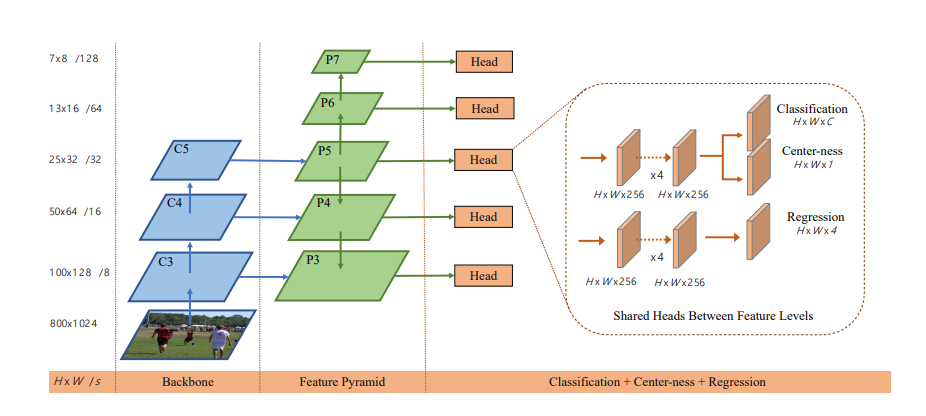
C3~C5は特徴マップ、P3~P7はFPNによる複数スケールの特徴マップを表します。左から順にバックボーンとなるネットワーク、複数サイズの特徴マップを生成するためのFPN(Feature Pyramid Network)、分類などを行う部分と分けられています。ネットワークは全ての層が畳み込み層でできており、全結合層はないのが特徴です。
物体検出では物体のサイズ、スケールの違いが問題になりやすいですが、FCOSではFPNを用いることで複数スケールの特徴を学習することができます。FPNについてより詳しく見ていきましょう。
FPN(Feature Pyramid Network)
FPNはLinらによって2017年に提案されたモデルで(Lin et al., 2017, “Feature Pyramid Networks for Object Detection”)、複数スケールでの画像認識を効率的に行うために畳み込みニューラルネットワークを用いたシンプルなエンコーダ・デコーダ構造のネットワークです。以下の図のように、複数スケールの畳み込みを砂時計みたいな形に繋げます。U-Netなどで用いられているのと同様にスキップ接続も用いたエンコーダ・デコーダ構造となっています。

こうすることで、序盤や中盤の特徴を最後まで伝えることができ、様々なスケールの特徴を学習することが可能となります。よって、FPNを用いると物体検出におけるサイズ・スケールの違いに強くなる上、計算も効率的に行うことできます。
しかし図1を見てこのモデルと構造が大分違くないか、と思われたかもしれませんが、FCOSにおいてはバックボーンネットワークの特徴マップをFPN側に図2のスキップ接続のように渡すということを行っています。つまり、図2のエンコーダ部分=バックボーンネットワークということで、そのバックボーンネットワークの特徴マップが図2のデコーダ部分=FPN側に渡されます。なお、バックボーンネットワークとしては主にResNetが使われます。
FOCSの出力とアンビギュアスサンプル
図1右のように、FCOSはピクセル毎に分類ラベルと中心性スコア、4次元ベクトルの3つを予測結果として出力します。4次元ベクトルはl, t, r, bの4つの値を持ちます。これは以下左の画像のように対象ピクセルからボックスの4辺までの距離を示しており、つまりバウンディングボックスの形状を示したものです。
アンカーベースの手法では画像上のある位置について複数のバウンディングボックス候補を生成してその中から適切なものを残すのに対し、FCOSではある位置について4次元ベクトルを予測します。
4次元ベクトルの値は物体を囲むボックスの面積が最小となるように学習されます。また、重要な点として、オブジェクトの中心から離れた点を中心としたボックスを生成してしまうことを防ぐためにcenterness(中心性スコア)というインデックスを学習対象に加えています。
最終的に、ピクセル毎の分類、4次元ベクトル、中心性スコアに基づいて検出された物体の位置とクラスが予測されます。
しかし、図2右のように、あるピクセルが複数のバウンディングボックスに入ってしまう状況も考えられます。このようなサンプルをアンビギュアスサンプル(ambiguous sample)と呼び、学習精度の低下につながることが知られています。
このようなアンビギュアスサンプルはたくさん発生してしまうのではないかと思われたかもしれませんが、ほとんどのアンビギュアスサンプルは異なるサイズのオブジェクト間で発生します。FPNのところで説明した通り、FOCSでは複数スケールの特徴の学習を複数スケールの畳み込みで行うわけですが、FOCSではこの際に各スケールにおけるボックスのサイズを制限します。つまり、 max(l, t, r, b) < 閾値 みたいな感じです。こうすることで、FCOSでは異なるサイズのオブジェクト間で発生するアンビギュアスサンプルをある程度抑制しています。
FCOSの実装
では、簡単にFCOSを実装してみましょう。今回はバックボーン~FPNあたりまではほぼ論文通りに実装します。
import torch
import torch.nn as nn
import torchvision.models as models
class BackboneWithFPN(nn.Module):
def __init__(self, backbone):
super(BackboneWithFPN, self).__init__()
# ResNetの最初の層
self.conv1 = backbone.conv1
self.bn1 = backbone.bn1
self.relu = backbone.relu
self.maxpool = backbone.maxpool
# ResNetの各レイヤーを取得 (layer1 ~ layer4)
self.layer1 = backbone.layer1
self.layer2 = backbone.layer2
self.layer3 = backbone.layer3
self.layer4 = backbone.layer4
# チャンネル数を256に変換するための1x1の畳み込み層
self.lateral_conv1 = nn.Conv2d(2048, 256, kernel_size=1)
self.lateral_conv2 = nn.Conv2d(1024, 256, kernel_size=1)
self.lateral_conv3 = nn.Conv2d(512, 256, kernel_size=1)
#p6, p7用の畳み込み層
self.conv6 = nn.Conv2d(2048, 256, kernel_size=3, padding=1)
self.relu6 = nn.ReLU()
self.conv7 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
# FPNの3x3畳み込み層
self.fpn_conv1 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.fpn_conv2 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.fpn_conv3 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
def forward(self, x):
# ResNetの最初の処理
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x) # [N, 64, H/4, W/4]
# ResNetの各層から特徴マップを抽出
x = self.layer1(x)
c3 = self.layer2(x) # [N, 512, H/8, W/8]
c4 = self.layer3(c3) # [N, 1024, H/16, W/16]
c5 = self.layer4(c4) # [N, 2048, H/32, W/32]
# 1x1 畳み込みでチャンネル数を256に揃える
p5 = self.lateral_conv1(c5) # [N, 256, H/32, W/32]
p4 = self.lateral_conv2(c4) # [N, 256, H/16, W/16]
p3 = self.lateral_conv3(c3) # [N, 256, H/8, W/8]
# FPNのトップダウンパス処理
p4 = p4 + nn.functional.interpolate(p5, scale_factor=2, mode="nearest")
p3 = p3 + nn.functional.interpolate(p4, scale_factor=2, mode="nearest")
# P6, p7の処理
p6 = self.conv6(c5) # [N, 256, H/64, W/64]
p7 = self.conv7(self.relu6(p6)) # [N, 256, H/128, W/128]
# その後、通常の畳み込みを適用
p3 = self.fpn_conv1(p3)
p4 = self.fpn_conv2(p4)
p5 = self.fpn_conv3(p5)
return [p3, p4, p5, p6, p7]図1と照らし合わせて、最終的にp3~p7までをちゃんと返していることを確認してください。
続いて、Head部分の実装です。論文ではバウンディングボックス予測用ネットワークと中心性予測用ネットワークが部分的に共有されていますが、今回は別々に実装しています。
class FCOSHead(nn.Module):
def __init__(self, num_classes, in_channels=256):
super(FCOSHead, self).__init__()
# クラス予測
self.cls_head = nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels, num_classes, kernel_size=3, padding=1)
)
# バウンディングボックス予測
self.regression_head = nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels, 4, kernel_size=3, padding=1) #出力は4チャンネル
)
# 中心性予測
self.centerness_head = nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels, 1, kernel_size=3, padding=1) #出力は1チャンネル
)
def forward(self, features):
cls_outputs = []
regression_outputs = []
centerness_outputs = []
for feature in features:
cls_outputs.append(self.cls_head(feature))
regression_outputs.append(self.regression_head(feature))
centerness_outputs.append(self.centerness_head(feature))
return cls_outputs, regression_outputs, centerness_outputs最終的にFCOSモデルは次のようになります。
class FCOS(nn.Module):
def __init__(self, num_classes, backbone):
super(FCOS, self).__init__()
self.backbone = BackboneWithFPN(backbone)
self.head = FCOSHead(num_classes)
def forward(self, x):
features = self.backbone(x) # 特徴マップ(p3~p7)
cls_preds, regression_preds, centerness_preds = self.head(features) # FCOSのヘッド処理
return cls_preds, regression_preds, centerness_preds学習させる環境はありませんが、ダミーのデータを入れて出力がちゃんと出るか確認してみます。
ちゃんとしたデータセットを使うと学習に時間がかかってしまう関係で、今回は実際に物体検出させるところまではやりませんが、だいたい仕組みが理解できたのではないかと思います。
まとめ
今回はアンカーフリーの物体検出アルゴリズムであるFCOSについて解説しました。FPN、アンビギュアスサンプルなどの重要な点もよく復習しておきましょう。










