


Grad-CAM(Gradient-weighted Class Activation Mapping)はCAM(Class Activation Mapping)という画像AIの判断の可視化を行う手法を改良したものです。CAMは画像解析モデルの判断根拠を可視化する技術です。しかし、CAMは可視化方法の性質から適用できるモデルの構造がかなり制限されます。そこで、モデルの構造にとらわれず画像解析AIの判断根拠を可視化する技術としてGrad-CAMが考案されました。
Grad-CAMとは
Grad-CAM は、CAM が抱えていた制約を取り除くために考案された手法 です。CAM では、可視化のためには、モデルが直感的に重要度が分かるような全結合層を使用している必要がありました。そのため、単純な全結合層(FC層)を持つ CNN にしか適用できず、VGG のような複雑な全結合層を持つネットワークでは使用できないという問題があったのです。
具体的には、下記の画像のような 単純な全結合層を持つ場合は、最終畳み込み層がどれほどクラスへ寄与しているかが分かりやすい構造(最終層の畳み込み結果の加重平均を取っているだけ)になっています。CAMはこのわかりやすさを前提にした方法を取っています。
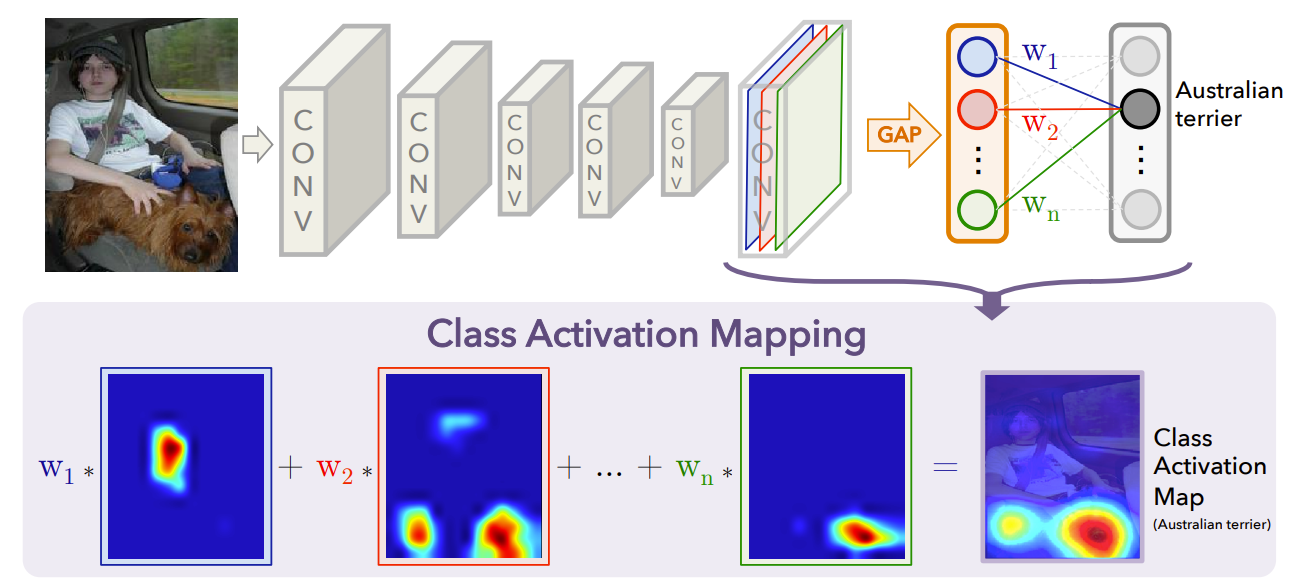
一方で下記の画像のように、複数の全結合層を持つ画像解析モデルの場合には、全結合層が複数あることで、最終的な畳み込み結果がどのようにクラスへ寄与しているのか判断が非常に難しくなり、CAM を使用することができないというわけです。
そこで登場したのが Grad-CAM(Gradient-weighted Class Activation Mapping)です。
Grad-CAMは勾配を使用してクラス判定への寄与を評価するため、画像解析モデルがどれほど複雑な全結合層を持っているかに影響されません。畳み込み層と全結合層の間に大きな FC 層があろうと、あるいは別の構造を取っていようと、最終畳み込み層と勾配さえ利用できれば可視化が可能になります。このようにGrad-CAM はほとんどの CNN アーキテクチャに適用できるより汎用性の高い方法 です。
Grad-CAMの使用結果
下記の画像はGrad-CAMを猫の画像に適用した結果です。画像の結果からモデルは猫の顔に注目して画像を猫と判断していることが分かります。このようにGrad-CAMは画像解析モデルを可視化することができます。

Grad-CAMの仕組み
Grad-CAMの概要
Grad-CAM は勾配を活用した手法です。CAM の場合は、全結合層では最終畳み込み層の結果にただ重みを掛けただけであったため、その重み自体が各最終畳み込み層の結果がクラスの判別にどれくらい貢献しているかを表していました。一方で複雑な全結合層の場合は、各ノードが複雑に関係しており、直接的に各最終畳み込み層の結果がクラスの判別にどれくらい貢献しているかを判断することはできません。そこでGrad-CAMは勾配に注目しました。
Grad-CAMがどのような勾配を活用するか
Grad-CAMでは注目するクラスと各特徴マップのピクセルとの勾配を利用します。この勾配は、各特徴マップの値が増加した際にどのくらいクラススコアが変化するかを表した値です。つまり、この値が大きいほどクラスの判断に貢献してるといえます。

もう少し細かい話をすると、CAMでは各特徴マップの重要度を直接かけられる重みで決めていたが、下記の式のようにその特徴マップに含まれるすべてのピクセルの勾配の大きさの平均を特徴マップの重要度としています。具体的には下記のような式になります。このようにしてGrad-CAMでは全結合層の構造に依存せずに各特徴マップの重要度を決定しています。
やってみよう
コード
以下はGrad-CAMのコードおよびその実験結果です。
import numpy as np
import tensorflow as tf
import cv2
import matplotlib.pyplot as plt
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions
# 1. ResNet50をロード (ImageNet学習済み)
base_model = ResNet50(weights="imagenet")
last_conv_layer_name = "conv5_block3_out"
last_conv_layer = base_model.get_layer(last_conv_layer_name)
# 2. 勾配を取得するためのサブモデル (最終畳み込み層 + 全体の出力)
grad_model = tf.keras.models.Model(
inputs=[base_model.inputs],
outputs=[last_conv_layer.output, base_model.output]
)
def preprocess_image(image_path, target_size=(224,224)):
img = cv2.imread(image_path) # (H,W,3) BGR
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# RGB
img = cv2.resize(img, target_size) # 224x224にリサイズ
img = img.astype(np.float32)[None, ...] # バッチ次元 (1,224,224,3)
img = preprocess_input(img) # ResNet50前処理
return img
def grad_cam(grad_model, image_path, class_index=None):
# 1. 入力画像の前処理
preprocessed_img = preprocess_image(image_path)
# 2. tf.GradientTape で勾配を計算
with tf.GradientTape() as tape:
conv_outputs, predictions = grad_model(preprocessed_img)
if class_index is None:
class_index = tf.argmax(predictions[0])
target_class_score = predictions[:, class_index]
grads = tape.gradient(target_class_score, conv_outputs)
# conv_outputs, grads: shape=(1,H,W,C)
conv_outputs = conv_outputs[0].numpy() # (H,W,C)
grads = grads[0].numpy() # (H,W,C)
# 3. チャネル方向に平均 -> alpha_k
pooled_grads = np.mean(grads, axis=(0,1)) # (C,)
# 4. conv_outputs × alpha_k → チャネル方向に合計
grad_cam_map = np.sum(conv_outputs * pooled_grads, axis=-1)
grad_cam_map = np.maximum(grad_cam_map, 0)
# 5. 正規化 (0~1)
eps = 1e-8
grad_cam_map -= grad_cam_map.min()
grad_cam_map /= (grad_cam_map.max() + eps)
return grad_cam_map
def overlay_gradcam(image_path, grad_cam_map, alpha=0.4):
raw_img = cv2.imread(image_path) # BGR
raw_img = cv2.cvtColor(raw_img, cv2.COLOR_BGR2RGB) # → RGB
H, W, _ = raw_img.shape
# (7,7) -> (H,W)
heatmap = cv2.resize(grad_cam_map, (W, H))
heatmap = (heatmap * 255).astype(np.uint8)
# BGR形式のカラーマップ
heatmap_color = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
# BGR -> RGB
heatmap_color = cv2.cvtColor(heatmap_color, cv2.COLOR_BGR2RGB)
# α合成: raw_img(RGB) & heatmap_color(RGB)
overlay_img = cv2.addWeighted(raw_img, 1 - alpha, heatmap_color, alpha, 0)
return raw_img, overlay_img
if __name__ == "__main__":
# 画像パスを合わせてください
image_path = ""
# (A) 予測を確認
input_img = preprocess_image(image_path)
preds = base_model.predict(input_img)
top_pred_index = np.argmax(preds[0])
decoded = decode_predictions(preds, top=5)
print("Top-5 Predictions:")
for (imagenet_id, label_name, score) in decoded[0]:
print(f"{imagenet_id} : {label_name} (score={score:.4f})")
# (B) Grad-CAM 計算
grad_cam_map = grad_cam(grad_model, image_path, class_index=top_pred_index)
# (C) オーバーレイ可視化
raw_img, cam_img = overlay_gradcam(image_path, grad_cam_map, alpha=0.5)
# (D) 結果表示
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
plt.imshow(raw_img)
plt.title("Original Image")
plt.axis("off")
plt.subplot(1,2,2)
plt.imshow(cam_img)
plt.title("Grad-CAM")
plt.axis("off")
plt.show()
実験結果

Grad-CAMの結果を見ると範囲が広くやや曖昧性が強いと感じました。これは勾配の大きさが重要度と直結しているとは限らないために起こっていると考えられます。その問題に関してのちにCNNの構造に依存せず、より直接的にモデルの寄与度を表す手法が登場します。
まとめ
本記事では、CNNモデルが画像をどのように判断しているかを視覚的に説明する手法「Grad-CAM」について解説しました。Gtad-CAMはCNNのアーキテクチャに依存しない手法として非常に重宝されてきた手法ですので是非覚えておいてください。









