


コンピュータビジョン分野において、画像中のどこに、何が写っているかを識別する物体検出は主要な研究テーマの一つです。今回はその物体検出アルゴリズムの中でも特にシングルショット手法として有名なYOLOやSSDについて触れながら、それらのアルゴリズムにおける問題を解決するハードネガティブマイニングについてまで解説していきます。
この記事は畳み込みニューラルネットワークについて基礎を理解してはいるが、実際にYOLOやSSDの論文を読んだことはないような方を読者として想定しています。
Contents
物体検出とは
通常の画像認識は画像に何が写っているかを判別するだけでした。これに対し、何が写っているかだけでなく画像中のどこに写っているかまでも検出するのが物体検出です。よって、物体の領域候補検出、クラス判定の二つの処理が必要となります。代表的なアルゴリズムとしてはfaster R-CNN、YOLO、SSDなどがあります。このうちfaster R-CNNは2段階に処理が分けられていますが、YOLO、SSDは物体位置の検出とそのクラス推定を同時に行う「シングルショット」手法として有名です。よって、今回はYOLO、SSDについて中心的に扱います。faster R-CNNの解説についてはこちらをご覧ください。
YOLO (You Only Look Once)
YOLOのアルゴリズム
YOLOはRedmonらによって2016年に提案された物体検出アルゴリズムです(Redmon et al., 2016, “You Only Look Once: Unified, Real-Time Object Detection”)。この手法は非常にシンプルかつ高速なのが特徴です。内容を簡単に説明すると、画像中にたくさんのバウンディングボックスをつくり、その中で確信度の高いものだけを残すということを行います。
まず、画像を以下図左のようにグリッドセルと呼ばれる領域に分割します。
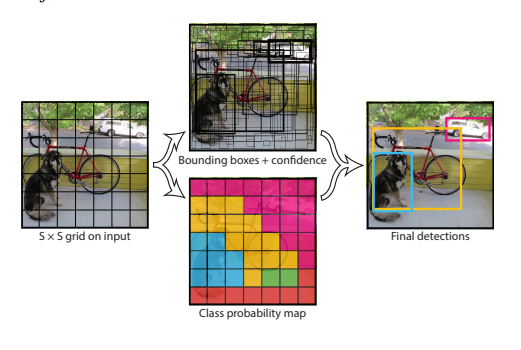
次に、上図中央のようにそれぞれのグリッドセルについてB個のバウンディングボックスと信頼度スコア(Confidence Score)を計算します。物体の中心があるグリッドセルに入る場合、そのグリッドセルはその物体の検出を担当します。ここではとりあえずたくさんボックスを作っておくということをしています。ここで、信頼度スコアは以下の式に基づいて、それぞれのボックスについて計算されます。
式だけ見るとわけがわからないですが、順を追って説明していきます。まず、Pr(Object)はボックスに物体が含まれる確率を表します。よって、ボックスに物体が含まれないときの信頼度スコアは0になります。また、IOUは予測と正解のIoU(Intersection over Union)を表しています。
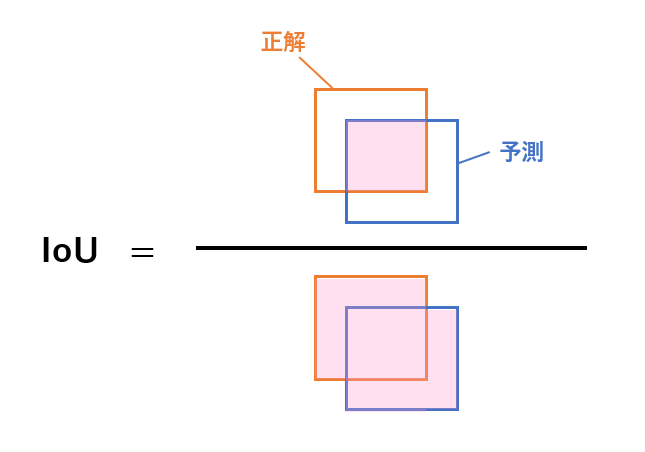
ここで、IoUというのはモデルによって予測されたボックス領域と正解ボックス領域の誤差を表す評価指標です。主に物体検出タスクでモデルの精度を測るために用いられ、以下の式で計算されます。
これは図で表すと以下のようになります。
ちなみに元の論文中ではPr(Object)とIOUの積を「信頼度スコア(Confidence Score)」とは別に「信頼度(Confidence)」と定義しています。ここまでの、バウンディングボックスの生成と信頼度の計算が図1中央上にあたります。
信頼度スコアに話を戻すと、さらに各グリッドセルでは一つのグリッドセルにつきC個(クラス数)の条件付きクラス確率Pr(Class_i |Object)を計算します。クラス確率の計算は図1中央下に該当します。この条件付き確率とPr(Object)を掛け合わせることで、条件付き確率の公式より、最終的な信頼度スコアが以下のように求まります。
よって、信頼度スコアというのはつまり「あるクラスがそのボックス内に出現している確率」と「そのボックスの予測がどれくらい正確か」を掛け合わせたもの、ということになります。この信頼度スコアに基づいて、たくさん作ったボックスのうちどのボックスを残すかを決めることになります。
結局、モデルはグリッドセル毎のバウンディングボックス情報x, y, w, h(ボックス中心のx座標、ボックス中心のy座標、ボックスの高さ、ボックスの幅)に加え、そのボックスの信頼度、の5つの情報をバウンディングボックスの数だけ予測し、さらにグリッドセル毎のクラスの予測も行うことになります。よって、損失関数はバウンディングボックスの座標誤差、信頼度の誤差、クラス予測の誤差の3つの情報の和として定義します(論文中ではもう少し複雑な定義がされています)。
YOLOのネットワーク構造
次に、元の論文中におけるネットワークは以下のような構造をしており、画像分類のためのGoogLeNetをもとにしています。
このネットワークの出力部分を見ると、7×7×30というサイズになっていますが、これは一見何を予測しているのかわからないかもしれません。
今回はS×Sのグリッドに分割、B個のバウンディングボックスを作成、C個のクラスを予測するとしますと、まずグリッド毎に前述した5つのバウンディングボックス情報を1グリッドセルあたりのバウンディングボックスの個数Bだけ予測するので予測のサイズはS×S×B×5となります。次に、グリッドセル毎にC個のクラスをS×S×Cだけ予測することになります。これらの和を取り、最終的な出力サイズはS×S×(B×5+C)となります。
今回のネットワークの場合、7×7のグリッドセルに分割し、2つのバウンディングボックスを予測し、データセットのクラス数は20を想定しています。よって、7×7×(2×5+20)=7×7×30になる、というわけですね。
まとめると、YOLOの流れは
- 入力画像をグリッドに分割
- 各グリッドセルについて複数のバウンディングボックスと信頼度スコアを予測
- 信頼度スコアに基づき、どのボックスを残すか選択
となります。
YOLOの実装について
YOLOを論文通りに実装しようとするとモデルの構造が複雑な上、GPUで学習させても時間がかかるため、今回は実装については紹介しません。ただ、torchhub上で公開されているものをダウンロードして試すことは容易ですので、興味がある方は調べてみるとよいでしょう。
SSD(Single Shot multibox Detector)
SSDのアルゴリズム
SSDはLiuらによって2016年に提案された物体検出アルゴリズムです(Liu et al., 2016, ”SSD: Single Shot MultiBox Detector”)。YOLOと同様、一度の推論で物体検出を行いますが、YOLOとは異なり、複数スケールの物体の検出に強いという特徴があります(厳密に言うと、YOLOもv3などでは細かいスケールの物体も検出できるようになっています)。
簡単に説明すると、この手法は複数の異なるスケールの特徴マップを用いることで複数のスケールでの検出を実現したものです。例えばfaster R-CNNでは一つの特徴マップに対して複数サイズの検出ボックスを適用することで複数のスケールでの検出を行うのに対し、SSDではそれぞれ異なるスケールを持つ複数の特徴マップを用います。
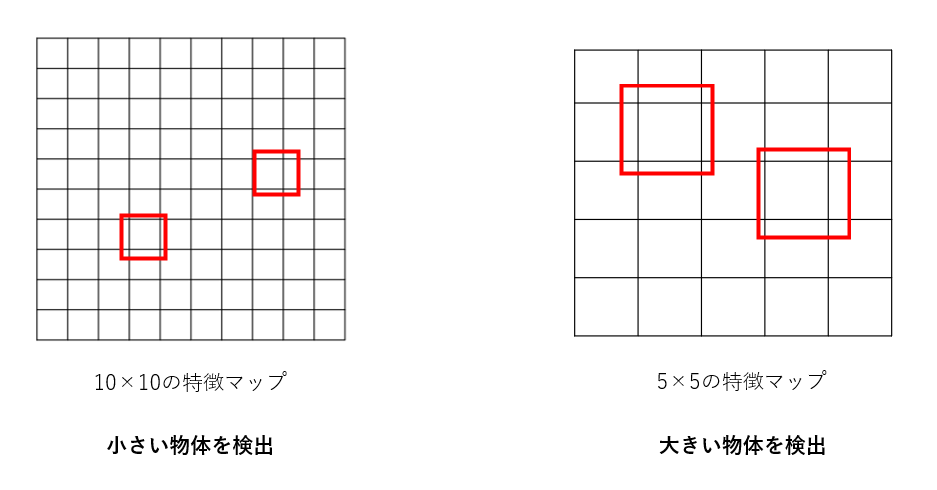
上図を見れば、グリッドサイズが小さい特徴マップでは小さい物体を、大きい特徴マップでは大きい物体を検出しやすいということが感覚的に理解できると思います。これらを組み合わせることにより、小さい物体から大きい物体まで幅広く検出することができます。
ところで上図を見ると、グリッドごとにボックスが配置されているように見えますが、実際にSSDでは各特徴マップについて、各グリッドセルごとにあらかじめサイズと縦横比が決まっている「デフォルトボックス」と呼ばれるボックスが関連づけられています。つまり、以下の図のようにデフォルトボックスが特徴マップに隙間なく敷き詰められた感じです。このような敷き詰めは畳み込みと同じ仕組みで行われています。
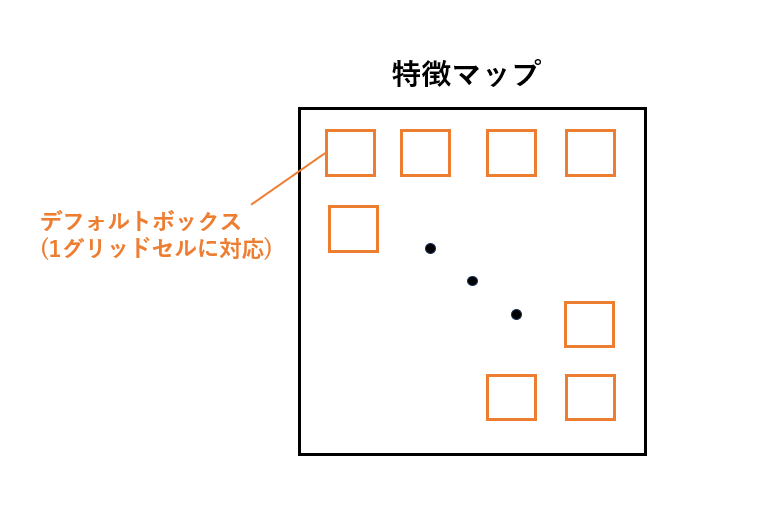
これは物体がどこにあるのかを推定するための基準となるものであり、これを利用して各グリッドセルごとに物体がある位置の誤差を計算します。また、各グリッドセルでは物体位置の誤差だけでなく、そのセルに物体がある場合、その物体が何なのか(クラス)の予測まで行います。
もう一つ重要なポイントとして、デフォルトボックスはそれぞれのセルごとに複数の縦横比のセットが用意されます。これにより、異なる縦横比の物体にも対応できるようになります。
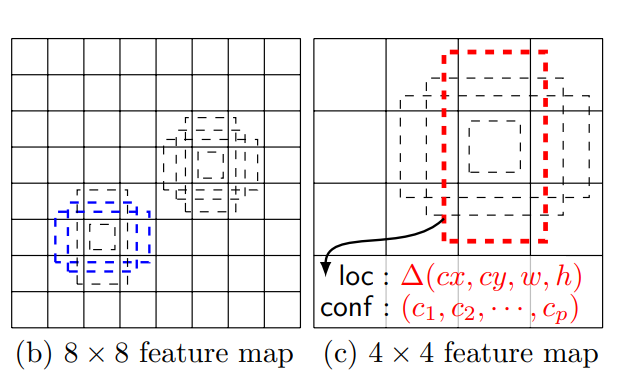
しかしこのようにデフォルトボックスが多いと複数のボックスが同じ物体を検出してしまい、さらにSSDではデフォルトボックスを隙間なく敷き詰めるため、単純にIoUを計算して正解ボックスに最も重なっているボックスを決定するのが難しいという問題があります。そこで、SSDではNon-Maximum Suppressionというアルゴリズムを用いて、重複するボックスの削除を行っています。
結局、SSDは学習に入力画像と正解ボックスが必要であり、各デフォルトボックスに対する正解ボックスとの誤差、クラスを予測するように学習を行います。よって、その損失関数は位置の予測誤差とクラス予測誤差の重み付き加重和となります。
SSDのネットワーク構造
元の論文中におけるネットワークの構造は以下のようになっています。画像分類モデルのVGG-16をベースとし、全結合層を畳み込み層に置き換えた上、分類層が切り捨てられそこにいくつかの畳み込み層が追加されています。追加された畳み込み層はだんだん大きさが小さくなっていっており、複数のスケールでの検出を可能にしています。以下の図では追加された層からそれぞれ矢印が伸びていますが、それぞれの層においても検出を行っているということです。
まとめると、SSDの流れは
- VGG-16ベースのネットワークで特徴マップを生成
- 特徴マップ上の各グリッドセルに対し、複数のデフォルトボックスを配置
- 各グリッドセルごとにクラスと物体位置を予測
- Non-Maximum Suppressionによる重複ボックスの削除
となります。
SSDの実装について
SSDについても、論文通りに実装しようとするといろいろ面倒なので今回は触れません。こちらもtorchhubにモデルが公開されているため、気になる方はダウンロードして試してみてもよいでしょう。
ハードネガティブマイニング
このように、ここまで紹介してきた方法ではいずれも複数のバウンディングボックス候補を生成し、その中で特定のものを残していました。しかし、画像はたいていその面積の多くを背景が占めるため、背景が多くの面積を占めるサンプルの数が多くなります。したがって、単純に全てのバウンディングボックスについて学習を行うと、データの偏りのせいで学習が上手くいかなくなってしまうことが知られています。
そこで、ハードネガティブマイニングという手法が用いられています。この手法では物体が存在するバウンディングボックス : 存在しないバウンディングボックス(ポジティブ対ネガティブ)の比が最大でも1 : 3になるように選び、学習を行います。こうすることでデータの偏りすぎを防ぎ、学習速度と安定性を向上させることができます。
まとめ
今回は代表的なシングルショット物体検出アルゴリズムであるYOLO及びSSD、さらにハードネガティブマイニングについて解説しました。いずれも非常に有名なモデルですので。









