


本記事では、コンピュータビジョン分野に大きな進展をもたらしたディープラーニングアルゴリズムであるCNN(convolutional neural network, 畳み込みニューラルネットワーク)について解説します。
Contents
畳み込みニューラルネットワーク(CNN)とは
CNN(convolutional neural network, 畳み込みニューラルネットワーク)は主に画像認識の分野で用いられるディープラーニングアルゴリズムです。データを学習することで入力画像から特徴量を抽出しそれらを区別することができるようになるため、ディープラーニングを画像認識の分野に応用する上で大変重要なものとなっています。
畳み込みニューラルネットワーク(CNN)の起源
まず、CNNがどのように生まれたのかを解説します。少しつまらないお話かもしれませんが、CNNを理解する上で知っておくべきことです。
画像データの学習と移動不変性
画像は縦×横の二次元データであることは感覚的にも理解できるかと思いますが、それならば形状を変更して画像を1次元のベクトルに変換して全結合層で計算してあげればよいようにも思えます。
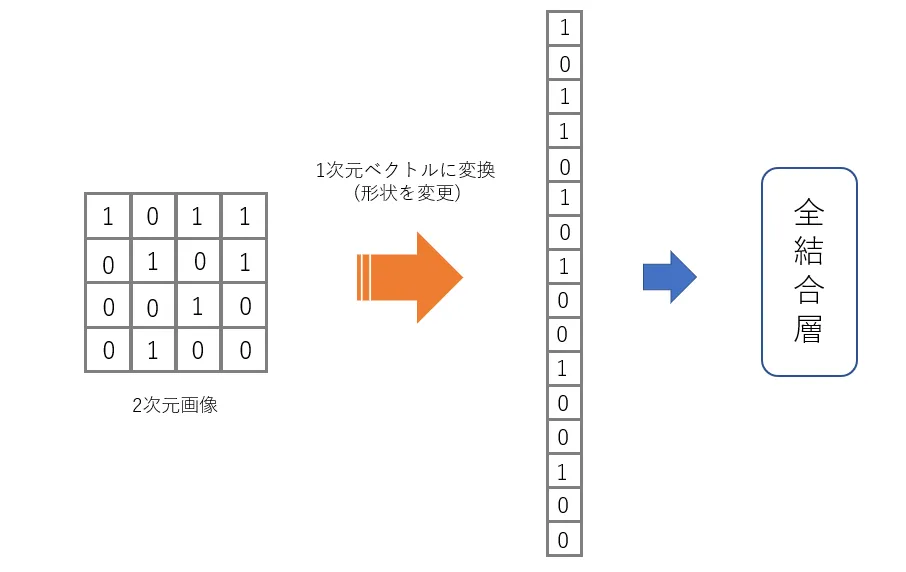
しかしここで問題となるのは、画像中の物体の位置が変化したとき、その物体を別の物体として認識してしまうということです。言い換えると、1次元のベクトルに変換して全結合層で計算する方法は移動不変性を持っていません。これはどういうことかというと、例えばある位置Aにウサギがいる画像(以下、画像A)で訓練されたモデルでは、別の位置Bにウサギがいる画像(以下、画像B)ではウサギを認識できないということです。
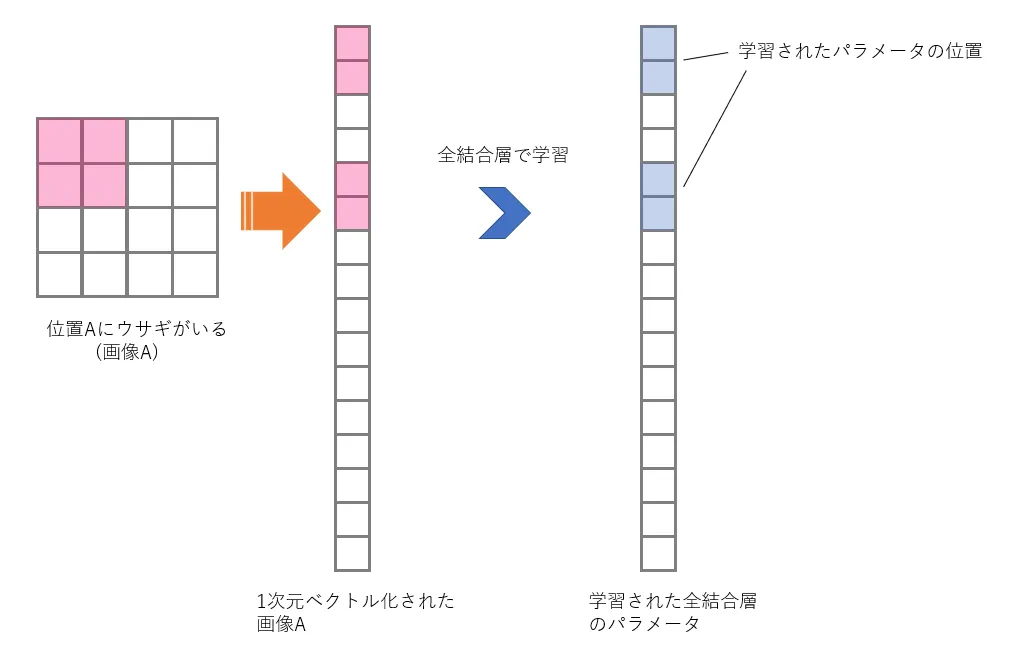
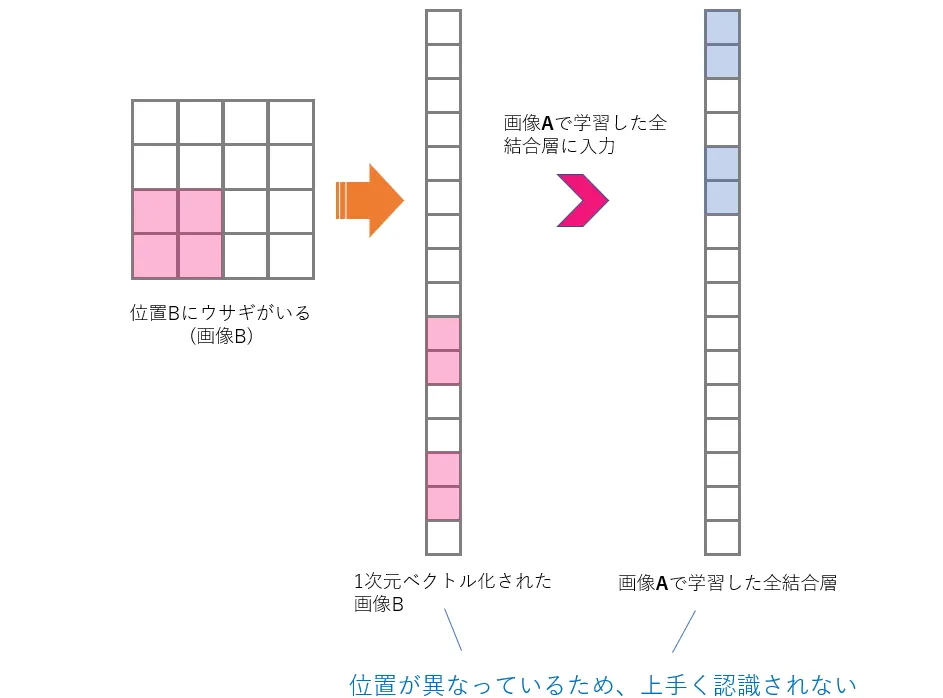
上の図では赤い位置にウサギがいるものとしています。この図は概略的なものですが、学習されたパラメータの位置が異なるために、画像Aを1次元化して全結合層で学習して得たモデルは、画像Bを1次元化したものの認識に用いることはできません。画像Bを認識するためにはもう一度画像Bを一次元化したものでパラメータを学習しなおす必要があります。これが、移動不変性をもっていないということです。
よって、局所的に物体を認識できる上でその物体が画像中で別の位置にあっても認識できるような移動不変性をもつ方法を考える必要が出てくることがわかります。
単純型細胞と複雑型細胞
以上の理由から、生物の脳の視覚野におけるニューロンの構造を模倣する方法が考案されました。我々生物の脳の視覚野には単純型細胞、複雑型細胞という二種類の細胞が存在し、それらが下の概略図のように目の網膜と接続しています。
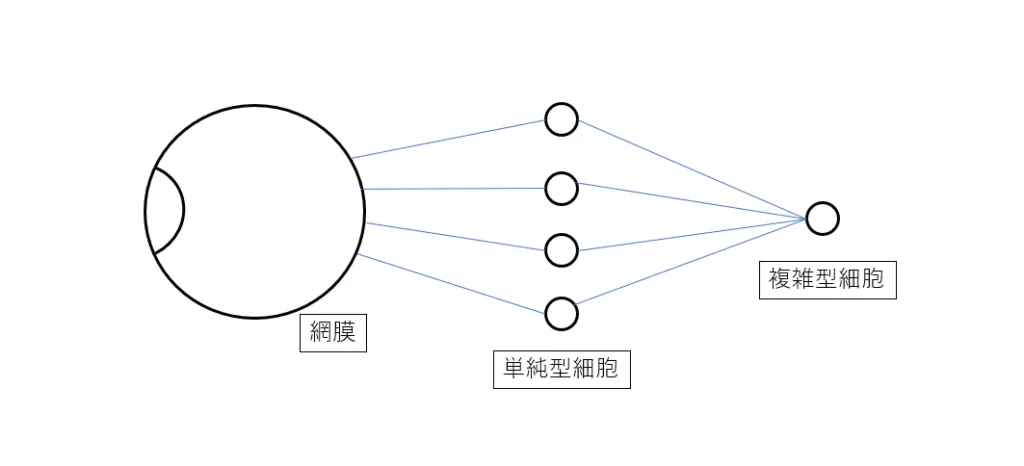
これらのような神経細胞に影響を及ぼす網膜上の範囲を受容野と呼びます。
ここでは詳しくは解説しませんが、単純型細胞は局所的な特徴を検出する働きがあります。しかし、単純型細胞の受容野では、同じ特徴、例えば縦の線などが検出されても、その特徴の位置がずれると別の特徴として認識されてしまいます。先ほどの全結合層で計算する方法では上手くいかないのと似ています。
そこで、複雑型細胞の出番です。複雑型細胞の受容野では、同じ特徴であれば特徴の位置が受容野内でずれていても同じ特徴として扱われます。したがって、複雑型細胞には受容野内における検出位置によらず認識を可能にする、移動不変性をもたせる役割があります。この複雑型細胞の働きを応用すれば移動不変性をもつモデルを作れそうということがわかるかと思います。
これらの単純型細胞、複雑型細胞の働きをモデル化したものがCNNというわけです。
畳み込みニューラルネットワーク(CNN)の構造
では、単純型細胞、複雑型細胞の働きを頭に留めながらCNNの構造を見てみましょう。CNNは入力層、畳み込み層、プーリング層からなっています。
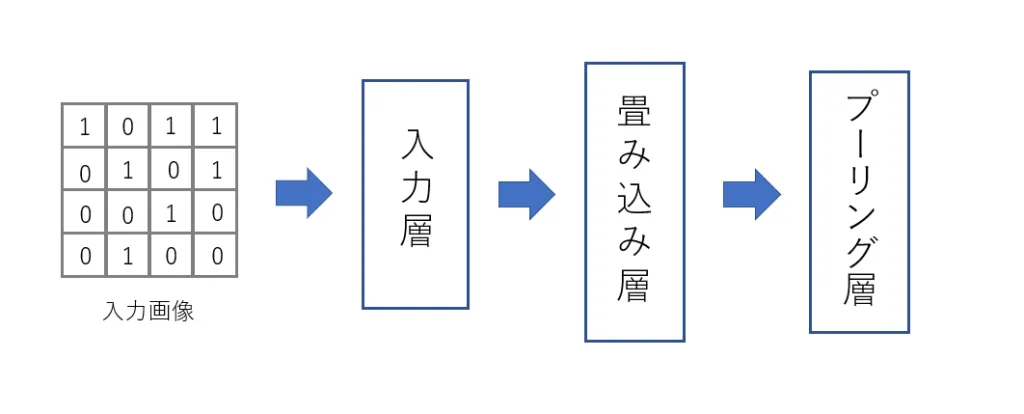
ここで、入力層は目でいうところの網膜、畳み込み層は単純型細胞、プーリング層は複雑型細胞にそれぞれ該当します。つまり、畳み込み層の役割は局所的な特徴量の抽出であり、プーリング層の役割は移動不変性の付与です。
畳み込み層とストライド
畳み込み層では、入力画像とは別にカーネルというフィルタのような重み行列を用意します。カーネルを図のように左斜め上から入力行列(画像)の全ての位置に移動させ、加重和を計算することで出力を得ます。ちなみに、このカーネルの移動間隔をストライドと呼びます。また、この出力は特徴マップなどと呼ばれます。
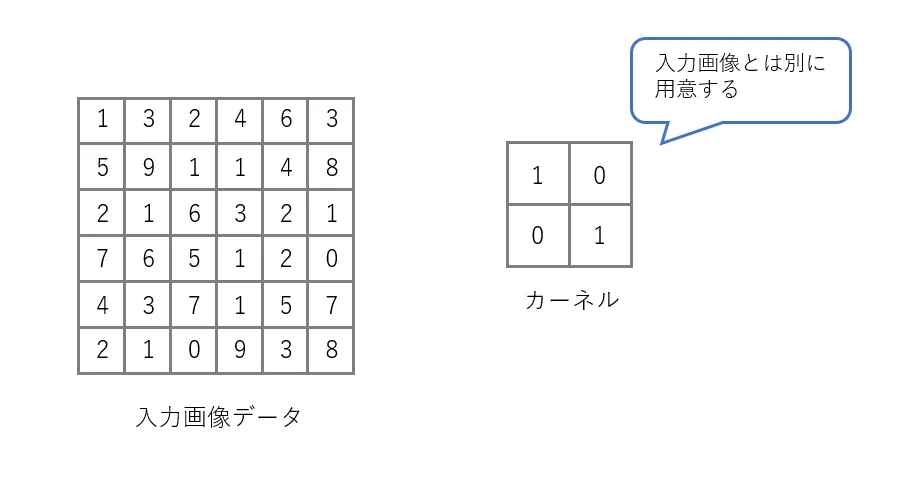
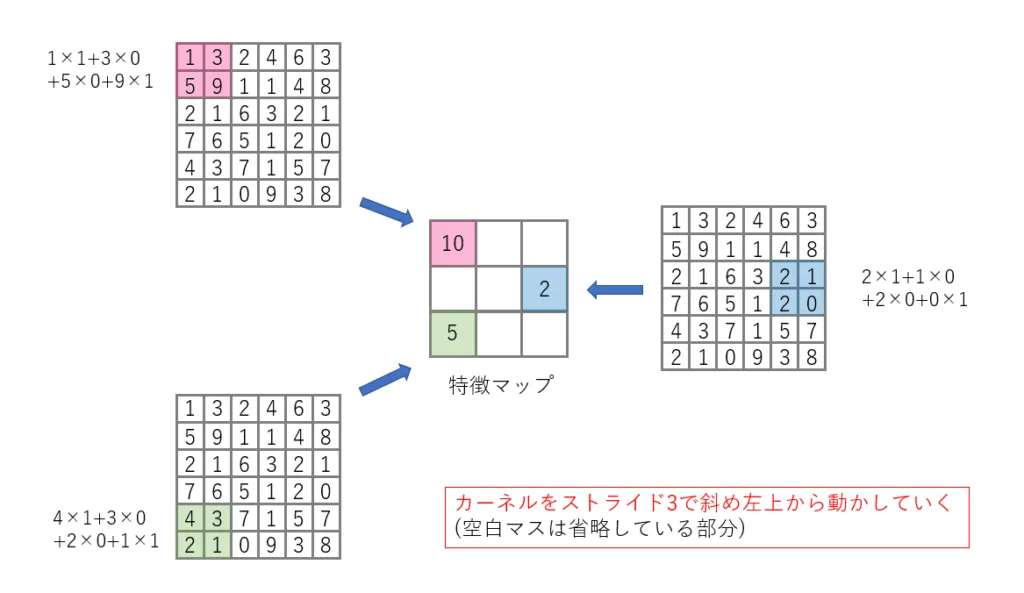
カーネルの重みは通常のニューラルネットワークにおける重みと同じくバックプロパゲーションによって更新されますが、同じカーネルの重みは一枚の画像全体に渡って同じものが用いられます。
プーリング層
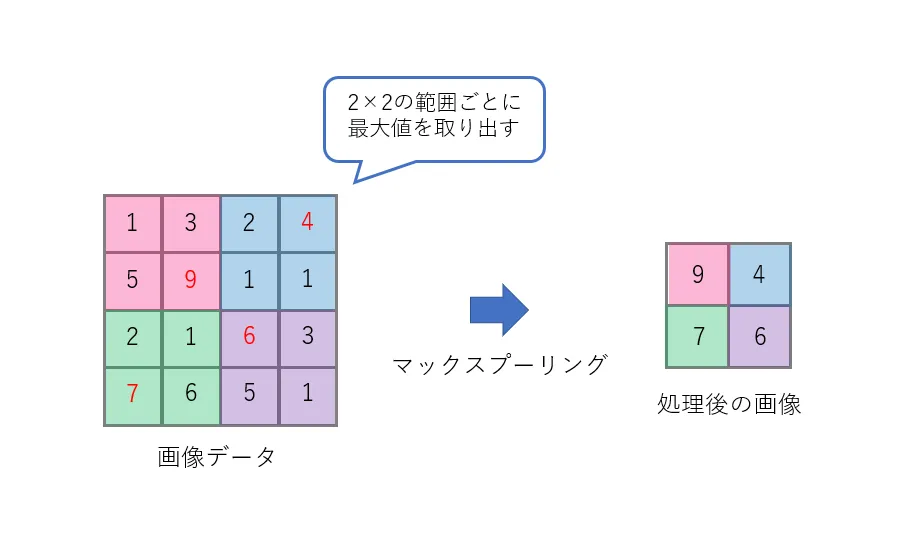
また、プーリング層では条件に応じて、画像内のある領域毎に画像のサンプリング操作を行います。例えば、図では画像内で2×2の範囲毎に最大値を取り出す操作(マックスプーリング)を行っています。以下、このプーリングを行う範囲をウィンドウと呼ぶことにします。
パディング
ちなみに、このように畳み込みやプーリングを行うと、出力画像のサイズが元の画像と比べて小さくなってしまうことが分かるかと思います。そこで、パディングという手法が存在します。これは畳み込みなどの処理を行う前の画像の周りに、0などの値をもつピクセルを追加することで画像サイズを拡大する手法です。
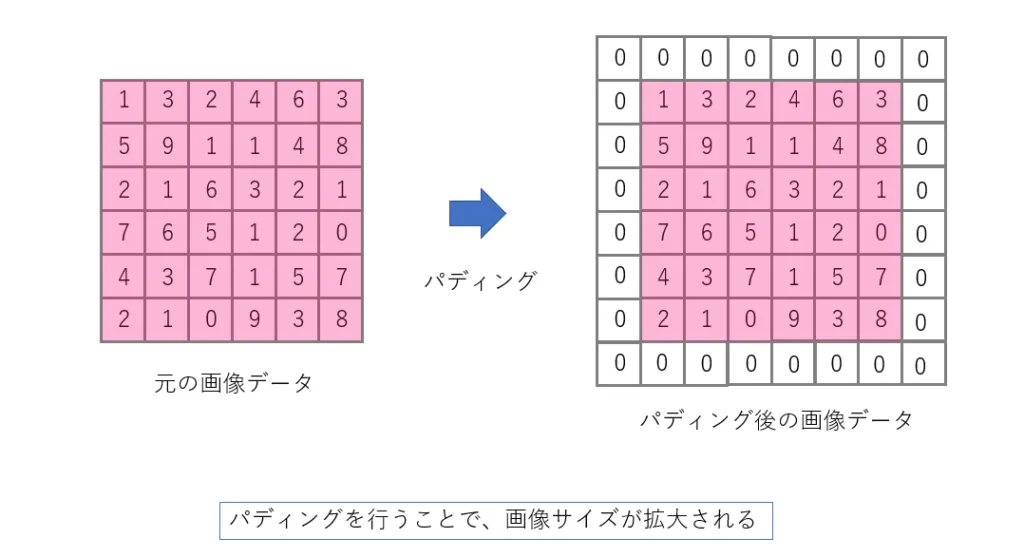
こうすることで画像の縮小を防ぎ、大きさを保つことができます。
CNNの構造についての簡単な説明は以上です。次からは、実際にCNNをPythonのディープラーニングフレームワークであるPyTorchを用いて実装していきます。
PyTorchを用いた畳み込みニューラルネットワーク(CNN)の実装
では、PyTorchを用いて簡単なCNNを実装していきましょう。今回は、MNISTデータという手書き数字の画像を分類するモデルを実装します。
モデルは、nn.Moduleを継承したクラスとして定義します。なお、以下のプログラムでは畳み込み層の後にプーリング層を適用した後、活性化関数(ReLU関数)を適用していますが、これは一般的にはプーリング層を適用した後に活性化関数が適用されるためです。プーリング層を適用して特徴マップのサイズを減らしてから活性化関数を適用することで、計算量を減らすことができます。また、畳み込み・プーリング処理で位置不変性が付与されているため、その後全結合層に通しても問題ありません。
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module): #nn.Moduleを継承したクラスとして定義
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, padding=2) #畳み込み層:(入力チャンネル数, 出力チャンネル数、カーネルサイズ、パディング)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, padding=2)
self.fc1 = nn.Linear(32 * 7 * 7, 128) #全結合層
self.fc2 = nn.Linear(128,10)
def forward(self,x):
x = torch.relu(F.max_pool2d(self.conv1(x), 2)) #畳み込み層の後のF.maxpool2dはプーリング層:(畳み込み層、ウィンドウサイズ)
x = torch.relu(F.max_pool2d(self.conv2(x), 2))
x = x.view(-1, x.size(1) * x.size(2) * x.size(3)) #テンソルを平らに(1次元に)する処理
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x ここで用いているmax_pool2dは範囲毎に最大値を取り出すプーリング操作を行います。今回はパディングは行いません。
また、このモデルを図示すると図 のようになります。
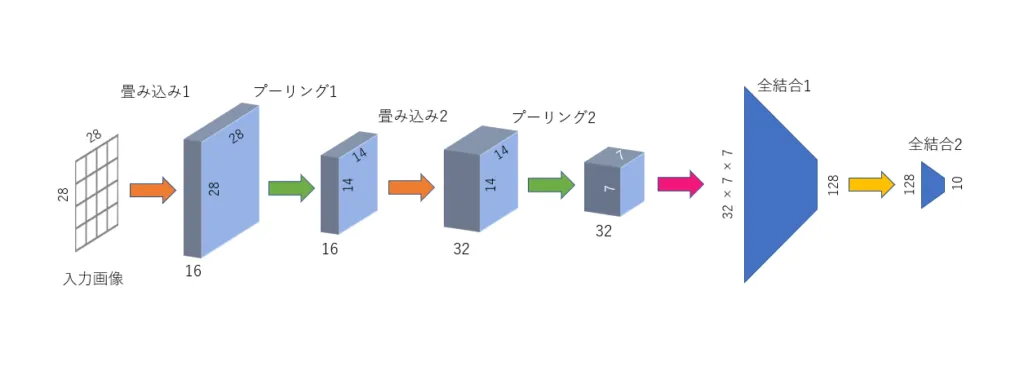
ここで注意すべきこととして、画像データの形状は(チャンネル数C(カーネルの数), 縦のピクセル数H, 横のピクセル数W)となります。
また、畳み込み層の出力において、入力画像の形状を\( (C_{in}, H_{in}, W_{in}) \)、出力後の形状を\( (C_{out}, H_{out}, W_{out}) \)として、出力後の縦の長さは
で表されます。ここでpaddingはパディングのサイズ、kernelはカーネルのサイズ、strideはストライドの大きさでデフォルトは1に設定されています。この式は横の長さについても成立します。
また、マックスプーリング層の出力においても、入力画像の形状を\( (C_{in}, H_{in}, W_{in}) \)、出力後の形状を\( (C_{out}, H_{out}, W_{out}) \)として、出力後の縦の長さ(及び横の長さ)は
で計算されますが、ここではkernelはプーリング操作におけるウィンドウサイズを表します。また、strideもウィンドウのストライドを表し、デフォルトはkernelと等しい値に設定されます。
なお、活性化関数の層では画像の形状は変化しないため、上の図では活性化関数の層は図示していません。これらを踏まえて、モデルのパラメータが正しく設定されているかを計算して確認してみることをおすすめします。
モデルさえ定義できればあとはデータセットを用意し、損失関数やオプティマイザを定義し、モデルに学習させるだけです。
#データローダーを作成
import torchvision.transforms as transforms
import torchvision.datasets as dataset
#データをテンソルに変更し、正規化する処理
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, ), (0.5, ))
])
#訓練データローダー
train_dataset = dataset.MNIST(root='/mnt/lib/mnist.npz', download=True, train=True, transform=transform)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
#(テストデータローダー)
test_dataset = dataset.MNIST(root='/mnt/lib/mnist.npz', download=True, train=False, transform=transform)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True)#損失関数、オプティマイザ
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.005, momentum=0.9)10エポック学習させ、その損失をグラフとして描画してみます。
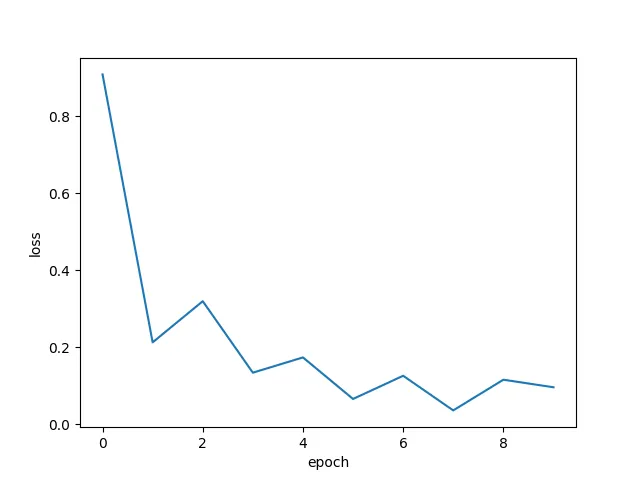
上手く損失が下がっていることが確認できるかと思います。
まとめ
今回はCNNについておおまかに解説しました。CNNは非常によく用いられるモデルですので、よく復習して内容をきちんと理解してみてください。











