


本記事では、深層学習において重要な活性化関数について解説します。本記事の構成は以下のようになっています。
Contents
シグモイド関数
まず、シグモイド関数について解説します。シグモイド関数は座標(0, 0.5)を基点として点対称となるS字型の滑らかな曲線で、その値は0から1までを取ります。深層学習におけるニューラルネットワークで用いられるシグモイド関数は標準シグモイド関数と呼ばれるものです。
標準シグモイド関数は厳密に式で書くと
と表されます。eはネイピア数と呼ばれる定数で、その値は約2.718…という無理数です。
この式をPythonの描画ライブラリであるMatplotlibを用いて描画してみましょう。
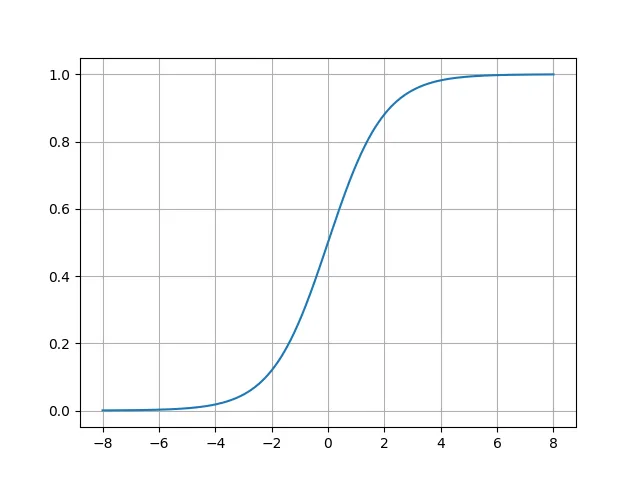
説明した通り、(0, 0.5)を中心として点対称なS字型の滑らかな曲線であり、その値は0から1までの値を取ることがわかります。
なお、標準シグモイド関数ではない一般的なシグモイド関数は
と表されます。Tnは正の定数で、温度パラメータと呼ばれるものです。この温度パラメータが1のときが標準シグモイド関数に相当します。温度パラメータの変化に応じて関数の形状がどう変わっていくのか、描画してみましょう。
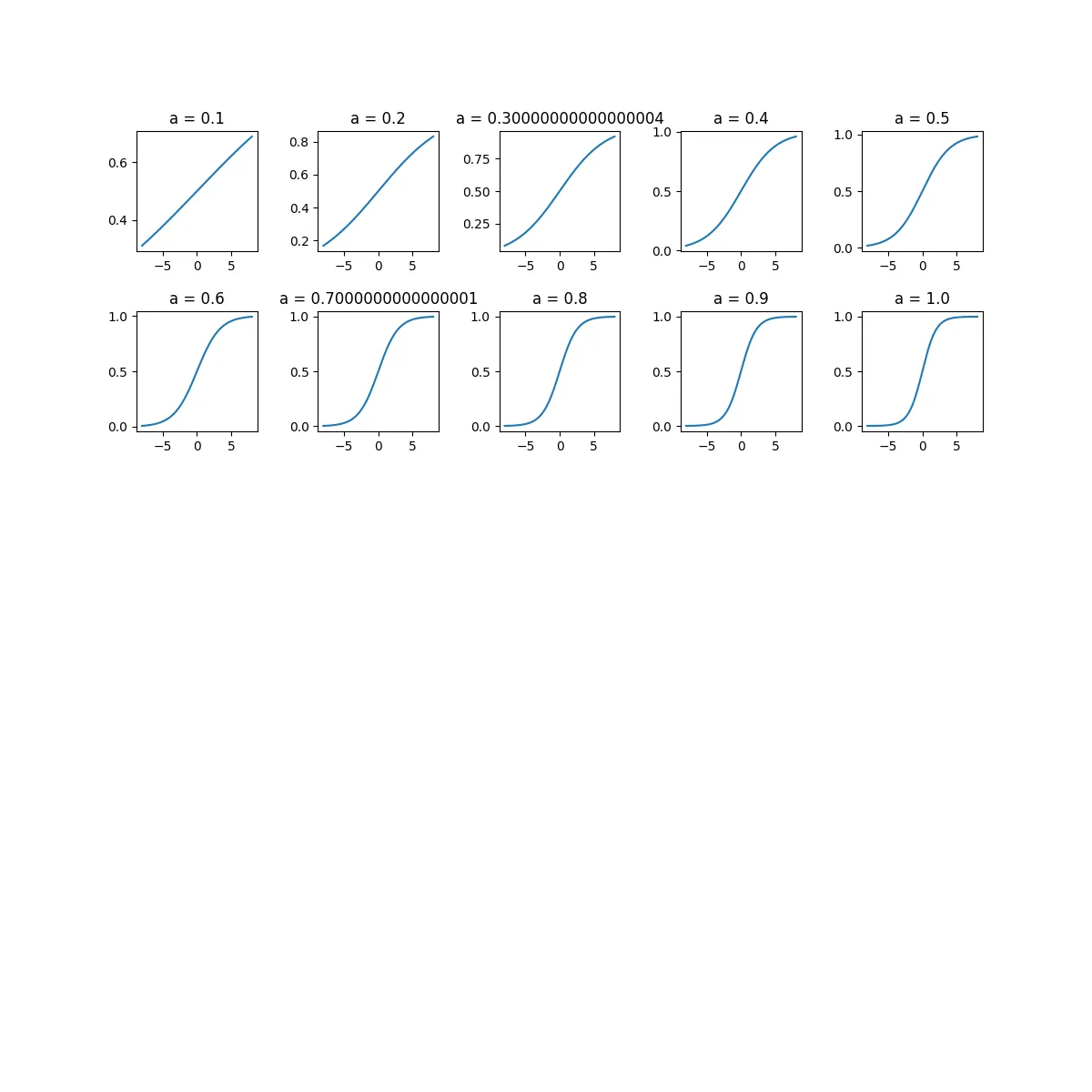
aの値が大きくなる、すなわち温度パラメータが小さくなるにつれてカーブが急になっていっていることがわかります。
なお、シグモイド関数の微分はシグモイド関数をf(x)として
のように簡単に計算することができます。ニューラルネットワークにおいてパラメータの更新過程では誤差逆伝播法という微分を利用した手法を用いますが、シグモイド関数はこのように微分後の関数を容易に求めることができるため、よくニューラルネットワークの活性化関数に用いられました。
ところで、この微分された\( \frac{df}{dx} \)の形状は以下の描画結果のようになり、その最大値は0.25です。
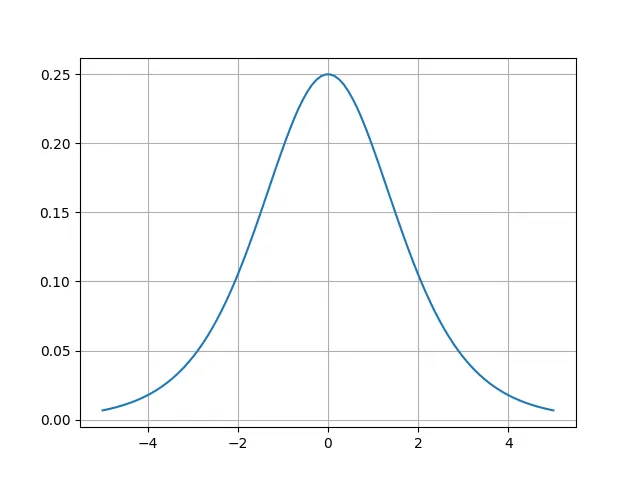
このため、微分を続けるといずれ微分した値が0に近づいてしまう、勾配消失という弱点があります。
ソフトマックス関数
続いて、Softmax関数について解説します。Softmax関数は出力の合計が1になるようにそれぞれの入力値を変換する関数です。
例えば、リンゴの画像、ミカンの画像、ブドウの画像を分類したいとき、それらをSoftmax関数に代入したところそれぞれ0.2, 0.3, 0.5という値に変換されたとします。ここで0.2 + 0.3 + 0.5 = 1と合計が1になっていますが、このようにSoftmax関数には出力値の合計が1になるという性質があります。合計が1になることから、Softmax関数を通して得られた出力値は確率として解釈することができます。このような、出力を確率として解釈することができるという性質からSoftmax関数は主に分類問題を解くためのニューラルネットワークにおいて、最後の出力層における活性化関数として用いられることが多いです。
なお、Softmax関数を数式で表現すると
となります。
ここでiは入力値のインデックス番号で、3番目の入力値x3に対してはそれに対応する出力値y3を出力するといった具合です。
では、Softmax関数をPythonで実装してみます。
ここでは三つの値を入力しましたが、対応する三つの出力が得られたことがわかります。出力の合計値を表示してみても、確かに1になっていますね。
ReLU関数、Leaky ReLU関数
次に、ReLU関数及びLeaky ReLU関数についてです。
ReLU関数
ReLU関数はランプ関数とも呼ばれ、その数学的な定義は
と非常にシンプルであることから、計算が非常に容易です。
また、すでに紹介したシグモイド関数も微分の計算が楽でしたが、微分していくと勾配が0に近づいていく、勾配消失という問題がありました。しかし、ReLU関数は微分しても勾配消失が起こりにくいです。これらの理由からReLU関数は現在、活性化関数として非常によく用いられています。
なお、ReLU関数はPythonによる描画も非常に容易です。
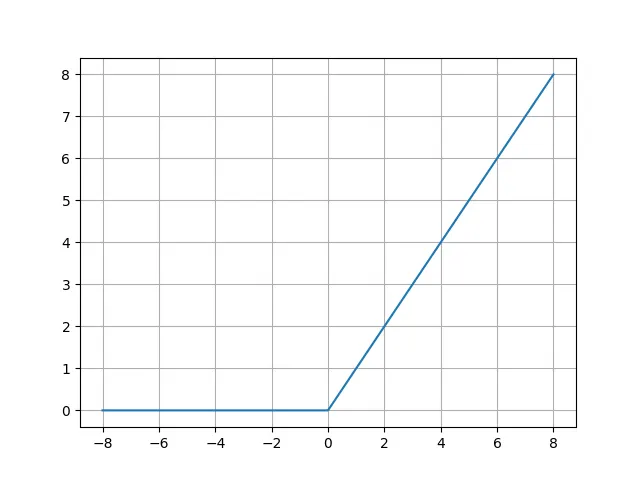
至ってシンプルなものとなっています。なお、x = 0で滑らかにつながっていないからそこでは微分できないのではないかという意見が出そうですが、ディープラーニングの計算過程ではx = 0で微分するような場面はほとんどないため、気にする必要はないです。一応x = 0における微分値は便宜的に0や1などの値に設定するというケースが多いです。
Leaky ReLU
次に、Leaky ReLU関数の解説をします。
Leaky ReLU関数はReLU関数を拡張したものです。ReLU関数ではxが0より小さいときの出力値が常に0となっていましたが、Leaky ReLU関数ではxが0より小さいときには入力値を-0.01倍した値を返します(0.01という数値は稀に他の値が代わりに用いられることもあります)。
すなわち、Leaky ReLU関数の数学的な定義は
[mathjax]$$ f(x)= \left\{ \begin{array}{lcl} -0.01x & (x<0のとき) \\[0.5em] x & (x\geqq0のとき) \\ \end{array} \right.$$[/mathjax]となります。
Pythonによる実装はReLU関数のときと同じく、非常に簡単です。
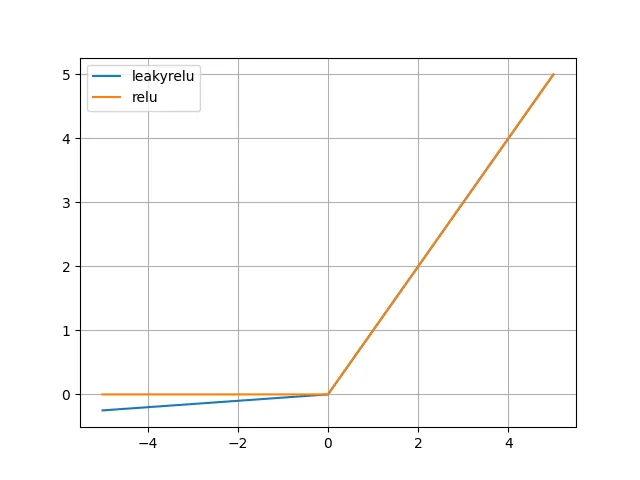
わずかにですが、Leaky ReLU関数の方はxが0より小さい範囲で出力値が下がっていっているのが分かるかと思います。
xが0より小さい範囲でも値をわずかに持つことから、ReLU関数と違ってx<0でも値が更新されます。これにより、ReLU関数を用いたときよりも良い結果をもたらす場合があります。
GELU関数
GELU関数は最近のニューラルネットワークにおいてよく用いられている活性化関数です。GELU関数は以下のように定義されます。
[mathjax]$$ Gelu = x\Phi(x) = \frac{x}{2} (1+erf(\frac{x}{\sqrt{2}}))$$ここで、Φは標準正規分布の分布関数、erfは誤差関数です。しかし、誤差関数は解析的な計算が難しいため近似が行われることが多く、
またはσをシグモイド関数として
と近似することができます。上の近似を近似1、下の近似を近似2としてこれらのGELU関数をプロットしてみると以下のようになります。
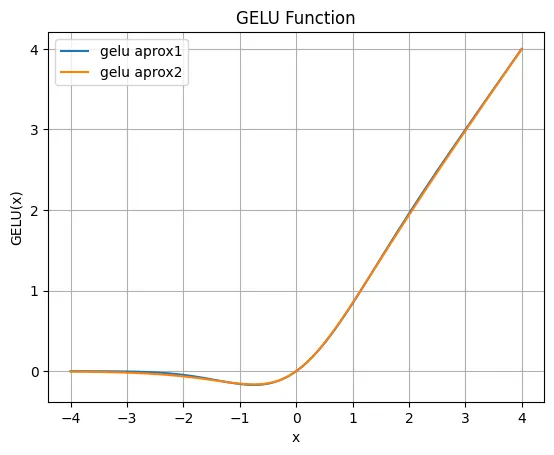
二つの近似には若干誤差がありますがどちらもReLU関数と非常に似ており、RELU関数を滑らかにしたようなものであることがわかります。
tanh関数(ハイパボリックタンジェント関数)
tanh関数も活性化関数に良く用いられます。tanh関数はシグモイド関数と形状が非常に似ており、座標(0, 0)を基点として点対称なS字型の曲線です。ただ、シグモイド関数と異なり出力は-1から1までの値を取ります。シグモイド関数は微分すると勾配消失の問題がありますが、tanh関数は微分した後の係数が0から1までの値を取るため、勾配消失が起こりにくいという利点があります。
tanh関数は数学的には
のように定義されます。よってPythonによる実装は
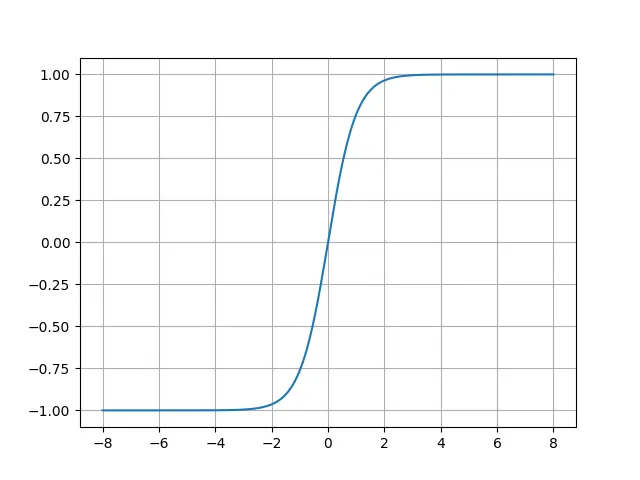
となります。プロットされた結果はシグモイド関数と似た形状ですが0を中心として点対称であることがわかります。
なお、tanh関数は微分した値(勾配)がシグモイド関数のときと比べて大きくなりますが、シグモイド関数と同じく勾配消失の問題があります。
ニューラルネットワークでの利用
ここまで活性化関数について紹介してきましたが、実際に活性化関数をニューラルネットワークで使用している例を見てみましょう。今回はフレームワークとしてTensorFlowを用い、MNISTデータセットの分類を行ってみることにします。TensorFlowの使い方に関しては簡単なチュートリアルの記事を別に挙げてありますので、そちらも参考にしてみてください。
まずはMNISTデータセットをロードします。TensorFlowの高レベルAPIであるkerasにはもともとMNISTデータセットが入っているためそちらを使います。
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
#MNISTデータをロード
mnist = tf.keras.datasets.mnist
#最初から訓練用と試験用にわかれている
(X_train, y_train),(X_test, y_test) = mnist.load_data()
#データの値が0から1までの間となるように正規化
X_train, X_test = X_train/255.0, X_test/255.0今回、モデルはSubclassing APIで実装します。ここで活性化関数が登場しますが、今回の活性化関数はシグモイド関数に設定します。なお、分類問題であるため最後の活性化関数はSoftmax関数を用いる点に注意してください。
import tensorflow as tf
class Net(tf.keras.Model): #tf.keras.Modelを継承したクラスとして作成
def __init__(self):
super(Net,self).__init__()
self.f1 = tf.keras.layers.Flatten(
input_dim = (28, 28)
)
self.f2 = tf.keras.layers.Dense(
units = 128,
activation = 'sigmoid' #活性化関数はシグモイド関数
)
self.f4 = tf.keras.layers.Dense(
units = 10,
activation = 'softmax' #最後だけ活性化関数はSoftmax
)
#順伝搬処理
def call(self, x, training = None):
x = self.f1(x)
x = self.f2(x)
y = self.f3(x)
return y
#モデルをNetクラスのインスタンスとして生成
model = Net()今回はtf.GradientTapeを用いずにコンパイルしてしまいましょう。もちろんtf.GradientTapeを用いても実装できますので練習してみたい方はtf.GradientTapeを用いてもよいでしょう。
オプティマイザはadam、損失関数はクロスエントロピー誤差を用います。
#コンパイル
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])学習はmodel.fitを実行することで行えます。
history = model.fit(X_train, y_train,
batch_size=100,
epochs=10,
verbose=1,
validat1on_data=(X_test, y_test)
)また、model.evaluateはモデルにデータを入れたときの正解率、損失を計算してくれます。
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=2)
print('\nTest accuracy:', test_acc)さらにmodel.predictは引数に設定したデータをモデルに入れたときの各データに対する予測結果を返します。
predictions = model.predict(X_test)今回は試しにインデックス番号0、すなわち一番最初のデータの推論結果がどうなったか見てみることにします。
import numpy as np
#予測結果
print(np.argmax(predictions[0]))
#実際の値
print(y_test[0])では、10エポックほど学習させてみます。少し時間がかかるかもしれません。
確かに予測結果が一致していることがわかります。
まとめ
本記事では、シグモイド関数、Softmax関数、ReLU関数、Leaky ReLU関数、GELU関数、tanh関数について紹介しました。いずれも頻繁に用いられる活性化関数ですので、知っておいて損はないと思います。また、実際にニューラルネットワークでどのように活性化関数が使われるのかも確認できたかと思います。途中でも述べましたが、TensorFlowについては別の記事でも解説しているので、そちらもあわせて確認してみるとよいと思います。










