


深層学習分野で「ニューラルネットワーク」という言葉を聞いたことがある人は多いと思います。今回はニューラルネットワークと呼ばれるディープラーニングの基礎技術について学習します。
Contents
序論
ニューラルネットワークとは
ニューラルネットワークとは、人間の脳内細胞(ニューロンと呼ばれる)を数式で表した数理モデルです。ニューロン内では、相互に接続されている複数のノードが存在します。それぞれのノードが発火し、信号が浅い層から深い層まで流れることで人間は物事を抽象的に分類することができます。ニューラルネットワークでは、これらの構造を数理モデルで模倣することで、データを浅い層から深い層まで分解し、膨大な情報(音声データ、画像データ)からパターンを見つけ出します。
ニューラルネットワークはなぜ大切なのか?
私たちの生活においてニューラルネットワークは身近に利用されています。例えば、
- 機械翻訳
- 株価予測
- 自動運転における物体認識
- 医療分野における癌の予測
- 不良品の分類
等のタスクにニューラルネットワークが用いられています。膨大なデータの高速処理が可能になったことからニューラルネットワークは注目を集めるようになりました。この章ではニューラルネットワークのモデルの中でも最も単純な全結合ニューラルネットワークについて学習していきます。
必要な数学知識
ニューラルネットワークでは多次元データ(多くの成分をもつデータ)を扱うため、行列計算の知識が必要不可欠です。その他、解析学で学ぶ多変数の微分積分の理解が必要となります。行列計算を扱う線形代数学については過去の体験型学習ブログで紹介しておりますので、そちらをぜひ活用ください。
ニューラルネットワークにおける線形演算
ここからは、ニューラルネットワークで行われている演算について説明していきます。ニューラルネットワークについて少し知ってる方は以下のような図を見たことがあるのではないでしょうか?
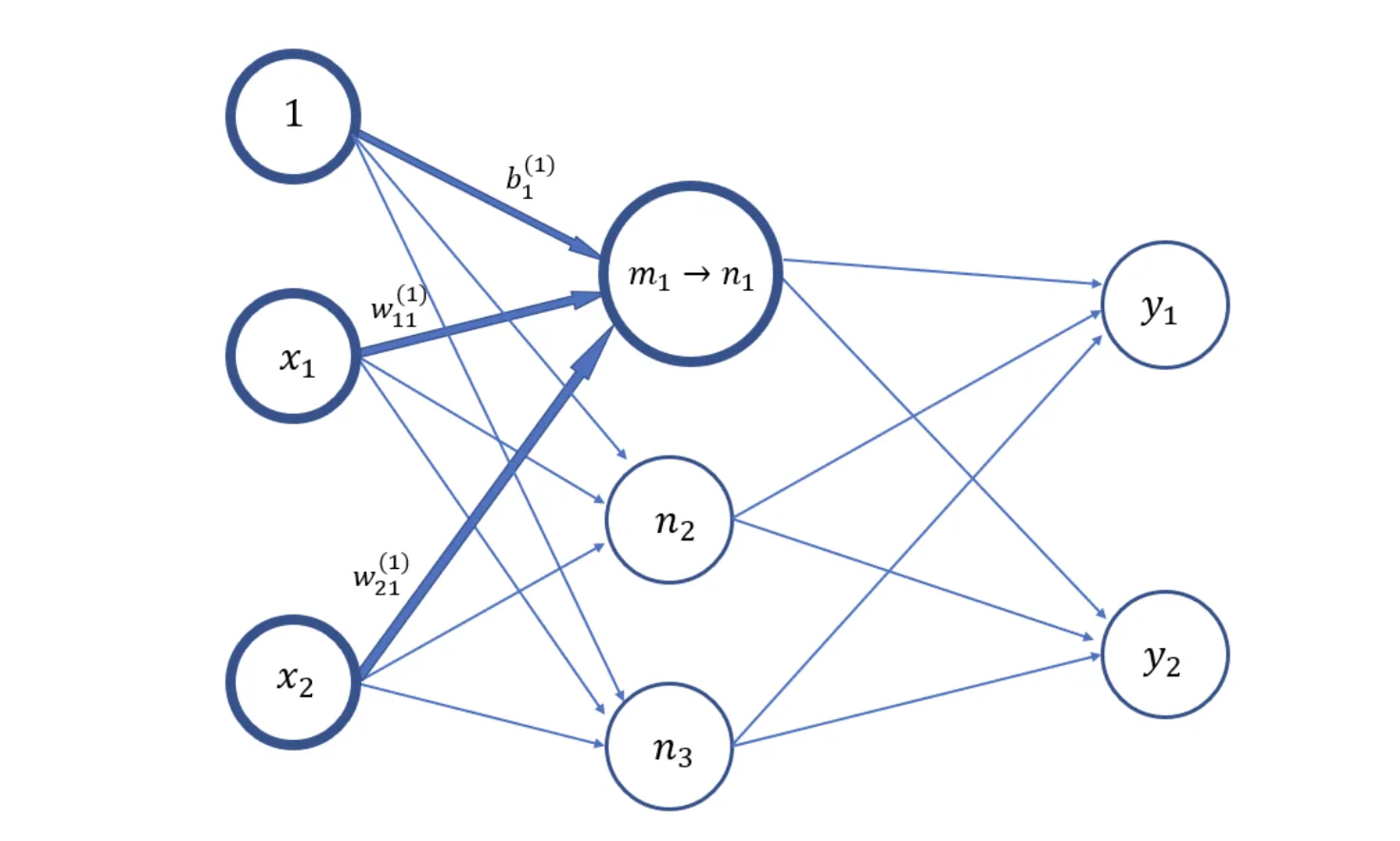
上のネットワークでは、入力\( x_1, x_2 \)を受け取り、中間の層の値\( n_1, n_2, n_3 \)を経て、\( y_1, y_2 \)を出力しています。では、どのような演算を行い中間層と出力層の値を計算しているのでしょうか? ここでは、まずは単純な計算を例にとって練習を行い、最終的に上の図のようなネットワークの理解を目指しましょう。
TensorFlowについて
本記事ではディープラーニングの実装にTensorFlowを使用します。Tensorflowとは、Google社が開発した深層学習用のライブラリーです。ディープラーニングの実装において、複雑なモデルを1から作るとなると途方もない時間がかかります。ライブラリーを使用することで、複雑なネットワークを分かりやすく記述することができます。
入力1出力1
まずは最も単純な例を参考にしましょう。
入力の次元が1,出力が1の単純な一次関数を考えます。
下のコマンドでTensorflowの基本モジュールをimportします。
入力に対して、一次関数の傾き(以降重みと呼びます)と切片(以降バイアスと呼びます)を作用させて出力を得るためのモデルを定義します。まずは、以下のコードを実行してみてください。
__init__()関数内のlayers.Dense(1)の部分で入力を一つ受け取り、出力を一つ返す演算を定義しています。そして、call()関数内で入力を渡し、出力を得るための計算を行っています。
上で実行したコードは、重みとバイアスをランダムにセットした時の出力を計算しています。では、重みとバイアスを任意の値に書き換えて出力が行列計算の値と一致しているか確かめてみましょう。
\( f(x)=2x-1 \) という一次関数に変更しました。では、任意の入力値を与えて出力を計算してみましょう。
入力が(1,2,3)に対して出力が(1,3,5)という結果になりました。
入力2出力1
次に入力が2,出力が1の二変数関数を考えてみましょう。
\( f(x)=ax+by+c = \begin{bmatrix} x & y & 1 \\ \end{bmatrix} \begin{bmatrix} a \\ b \\ c \\ \end{bmatrix} \)先程と異なる部分は入力が二つに増えたことです。それ以外の変更はないです。ではモデルを定義して、重みとバイアスの値を書き換えてみましょう。
上式のうち、a=1,b=2,c=−1としてみましょう。
では任意の入力を与え、出力を計算してみましょう。
入力が((1,2),(2,3),(3,4))に対して、出力(4,7,10)が得られました。
入力2出力2
今まで出力が一次元のみの例を考えてきました。最後の例として複数次元の出力を返すモデルの作成を行います。
\( (f_1(x,y),f_2(x,y))= (a_1x+b_1y+c_1,a_2x+b_2y+c_2) = \begin{bmatrix} x & y & 1 \\ \end{bmatrix} \begin{bmatrix} a_1 & a_2 \\ b_1 & b_2\\ c_1 & c_2\\ \end{bmatrix} \)入力2つに対して出力を2つ返すモデルを作成します。ステップ1、ステップ2と異なる部分は、__init__()関数においてlayers.Dense(2)となっており、1から2に変わっていることです。出力を2とするモデルを作成するため、このように変更しています。その後、過去二つの例と同様に、重みとバイアスの値を任意の値に変更します。
のように重みとバイアスの値を変更します。そして、出力を計算します。
出力、入力、重みの値を行列形式で表すと以下のようになります。
\( \begin{bmatrix} 1 & 3 \\ 3 & 7\\ 5 & 11\\ \end{bmatrix}=\begin{bmatrix} 1 & -1 & 1 \\ 2 & -2 & 1 \\ 3 & -3 & 1 \\ \end{bmatrix} \begin{bmatrix} 1 & -1 \\ 2 & -2\\ -1 & -1\\ \end{bmatrix} \)ニューラルネットワークの順伝播
多次元の入力に対して多次元の出力を返す演算について理解が進んだところで、実際にニューラルネットワークで行われている計算を行いましょう。
以降図3のようなネットワークについて考えていきたいと思います。
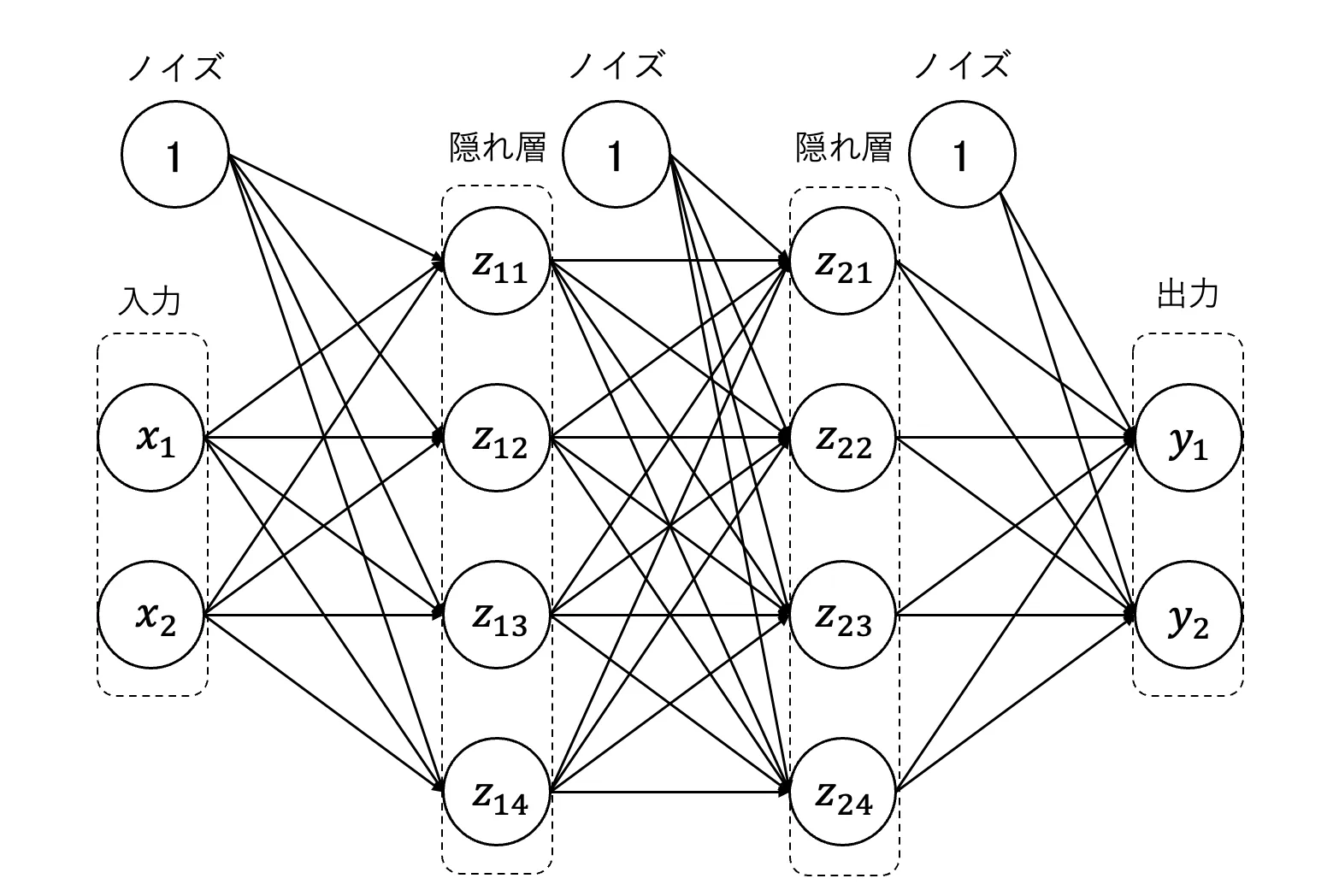
ネットワーク構造について少し説明をしたいと思います。はじめに\( x_1, x_2 \) を入力とします。次に先ほど紹介した行列演算を用いて、入力から隠れ層を計算します。ここで、隠れ層という言葉が出てきましたが、入力と出力までにいくつかの中間層を挟むことになります。この中間層のことを隠れ層と呼びます。では各層で行われている計算を行列の式で表して、ネットワーク全体を実装してみましょう。
入力-隠れ層1
はじめに入力-隠れ層1を見てみましょう。入力が2次元、出力が4次元になっています。これを式を用いて表すと \( (z_{11},z_{12},z_{13},z_{14})=\begin{bmatrix} x_1 & x_2 & 1 \\ \end{bmatrix} \begin{bmatrix} a_1 & a_2 & a_3 & a_4 \\ b_1 & b_2 & b_3 & b_4\\ c_1 & c_2 & c_3 & c_4\\ \end{bmatrix} \) となります。
隠れ層1-隠れ層2
次に隠れ層1-隠れ層2を見てみましょう。入力が4次元、出力が4次元になっています。これを式を用いて表すと \( (z_{21},z_{22},z_{23},z_{24})=\begin{bmatrix} z_{11} & z_{12} & z_{13} & z_{14} \\ \end{bmatrix} \begin{bmatrix} a_1 & a_2 & a_3 & a_4 \\ b_1 & b_2 & b_3 & b_4\\ c_1 & c_2 & c_3 & c_4\\ d_1 & d_2 & d_3 & d_4\\ e_1 & e_2 & e_3 & e_4\\ \end{bmatrix} \) となります。
隠れ層2-出力
次に隠れ層2-出力を見てみましょう。入力が4次元、出力が2次元になっています。これを式を用いて表すと \( (y_1,y_2)=\begin{bmatrix} z_{21} & z_{22} & z_{23} & z_{24} & 1 \\ \end{bmatrix} \begin{bmatrix} a_1 & a_2 \\ b_1 & b_2 \\ c_1 & c_2 \\ d_1 & d_2 \\ e_1 & e_2 \\ \end{bmatrix} \) となります。
※パラメータ数が多いため、重みの変数に同じ文字を繰り返し用いていますが、各レイヤー毎に異なるものだと考えてください。
順伝播の実装
上で定義したネットワークをTensorFlowで実装すると以下のようになります。
モデルの設計通り、二次元の出力が配列として得られました。このように入力データをモデルに入力して出力を得るまでの一連の計算プロセスを「順伝播」または「フォワードプロパゲーション」と表現することがあります。また、先頭のレイヤーを入力層、最後尾のレイヤーを出力層、それ以外の中間のレイヤーを中間層または隠れ層と呼びます。
m次元入力、n次元出力、k層
先程は、入力2次元、出力2次元、4層のニューラルネットワークを自作しました。
本演習では、例題より次元数を上げて、入力の次元が1000、出力の次元が10、間に二層の隠れ層を含んだ4層のニューラルネットワークを自作してみましょう。一つ目の隠れ層の次元を500、二つ目の隠れ層の次元を100としてください. 上の例を参考にしながら取り組んでみてください。Noneと書かれている部分に具体的な数字を記入しましょう。
入力の次元が(100,1000)、出力の次元が(100,10)となったでしょうか?
ニューラルネットワークの最適化
ここまで、ニューラルネットワークが入力を受け取り、出力を計算するところまで学習してきました。しかし、データを単に一方方向に流すだけでは、物事を予測したり分類したりできる賢いネットワークをつくることはできません。では、賢いネットワークを作るためにはどうしたらよいのでしょうか?
誤差関数
深層学習では、最適なパラメータの値に近づけるための指標として、まず損失関数(loss function)と呼ばれる関数を用います。損失関数とは、ニューラルネットワークが予想した値と正解値がどれだけ離れているかを数値化したものであり、この値が小さければ小さいほど良いわけです。ニューラルネットワークでよく用いられる損失関数として、二乗誤差(Mean Squared Error)と交差エントロピー(Binary Cross Entropy)があります。前者は回帰、後者は分類で用いられます。式で表すと以下のようになります。
二乗誤差
\( J=\sum_{i}(y_i – \hat{y_i})^2 \)
交差エントロピー
\( J=\sum_{i}y_i (log \hat{y_i}) \)\( y_i \) : i番目の正解データ、 \( \hat{y_i} \) : i番目の予測データ
最適化アルゴリズム
損失関数についてわかったところで、次に損失関数を用いてどのようにパラメータを最適化するのかについて学習しましょう。最適化アルゴリズムとして有名な勾配降下法(Gradient Descent)について見ていきましょう。
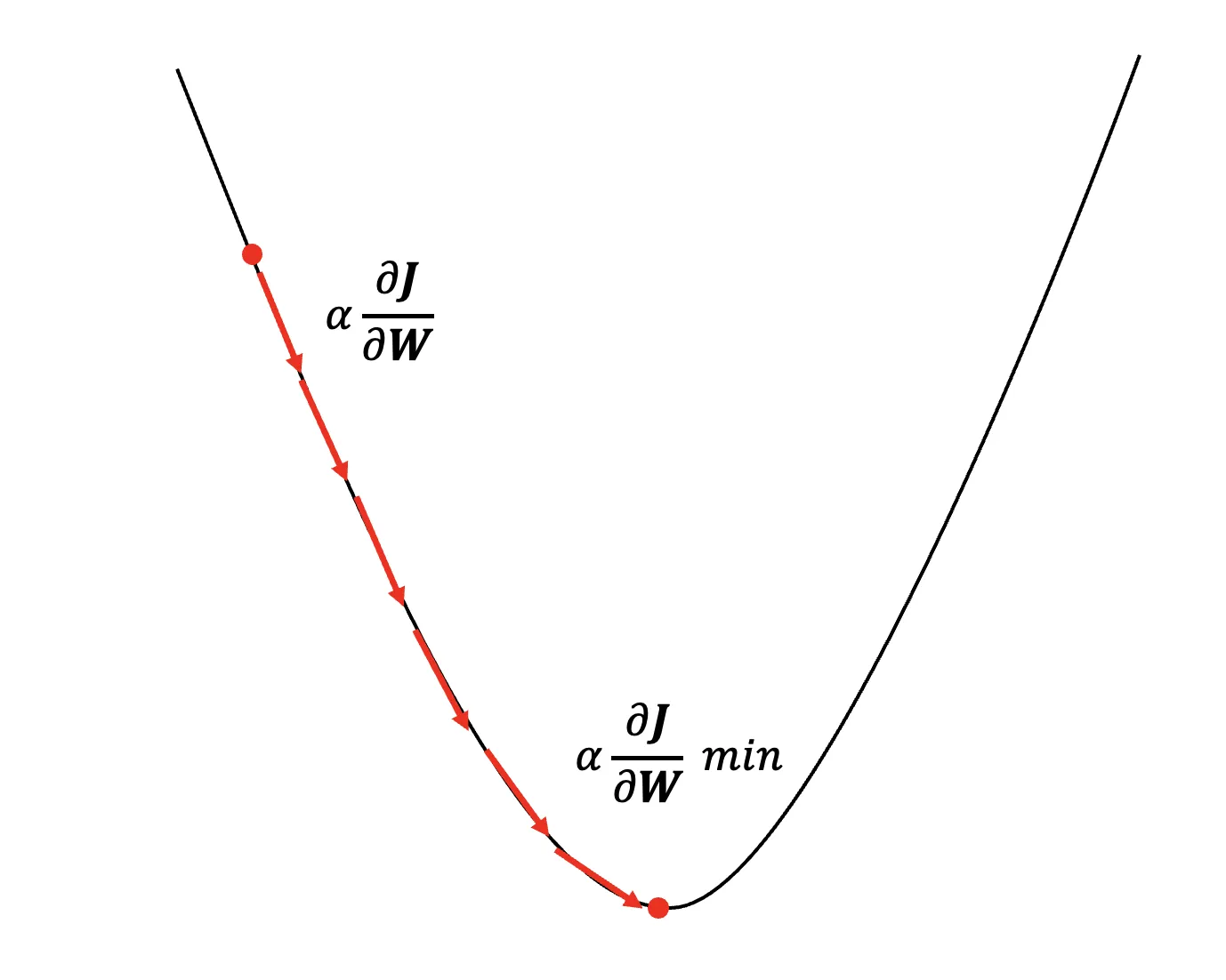
上の画像を見てください。矢印が谷底(損失関数の値が最小)に来るように少しずつ遷移していることがわかると思います。このように、損失関数の値が少しずつ変化しながら最適な方向に進んでいくようにパラメータの値を変化させていく方法を勾配降下法と呼びます。数式で表記すると以下のようになります。
\( \bf W = \bf W – \alpha \frac{\partial J}{\partial \bf W} \) Wは重み、Jは誤差関数、αは学習率(一度にどれだけ山を駆け降りるかを表す値)
ポイントは、損失関数 ? の微分を求めることです。しかし残念ながら多層ニューラルネットワークの微分値を直接計算することはとても難しいため、工夫が必要です。この工夫として生み出されたのが誤差逆伝播法(バックプロパゲーション)です。初心者には非常に難しい概念であるため、ここで詳しく説明するのは省略します。一言で誤差逆伝播法をまとめると、微分の連鎖律を用いて局所的な微分値をまず求め、それを組み合わせて全体の微分(端から端までの変分)を計算することができます。
[参考] 微分の連鎖律
TensorFlowの高レベルAPIは誤差逆伝播法を数行の簡単なコードで実装してくれるため、ここでは詳しい値を知らずとも大丈夫です。
簡単な回帰問題
ここまで、ニューラルネットワークの順伝播、逆伝播について学習してきました。概要だけ説明されてもよく分からないと思いますので、最後に簡単な演習に取り組んでみましょう。
取り組むこと
ボストンの住宅価格のデータセットを用いて、町別の犯罪率、一戸あたりの平均部屋数、固定資産税率などの特徴量から住宅価格の値を予測します。
まずはデータセットを読み込んでみましょう。
上のプログラムを実行してみると、訓練用データセットにおいてデータの行数が404、特徴量の数が13の行列です。検証用データセットは、予測値である住宅価格のデータです。 しかし、これでは特徴量の数が多すぎるという問題があるので、入力xの特徴量の数をある程度限定したいと思います。データセットに含まれる特徴量と予測量は以下の通りです。
- CRIM・・・犯罪発生率(人口単位)
- ZN・・・25,000平方フィート以上の住宅区画の割合
- INDUS・・・非小売業の土地面積の割合(人口単位)
- CHAS・・・チャールズ川沿いかどうか(1:Yes、0:No)
- NOX・・・窒素酸化物の濃度(pphm単位)
- RM・・・1戸あたりの平均部屋数
- AGE・・・1940年よりも前に建てられた家屋の割合
- DIS・・・ボストンの主な5つの雇用圏までの重み付きの郷里
- RAD・・・幹線道路へのアクセス指数
- TAX・・・10,000ドルあたりの所得税率
- PTRATIO・・・教師あたりの生徒の数(人口単位)
- B・・・アフリカ系アメリカ人居住者の割合(人口単位)
- LSTAT・・・低所得者の割合
予測量 PRICE・・・住宅価格
今回は住宅価格と関係のありそうな6,7,13番目の5つの特徴量を採用したいと思います。抽出したデータを可視化してみましょう。
入力と出力に何か相関性がありそうなのは、(RM,House Price), (LSTAT,House Price)の2組のペアーのようです。これにてデータの準備は終わりました。次にネットワークの作成、訓練に移りたいと思います。
今回は順伝播のところで用いた3層のニューラルネットワークを用います。ネットワークは以下のように定義されます。
今回用いるニューラルネットワークを作り終えたところで、次に最適化の手法を見ていきましょう。 tf.keras.optimizers.Adam(learning_rate=0.001) において勾配降下の手法ならびにどれぐらいの速度で山を駆け降りるかを決めるパラメータであるlearning_rateを設定しています。 その後、作ったモデルをnn_model.compile()関数でコンパイルします。引数にloss、metricsがありますが、これは損失関数やモデルの評価をする評価関数を選択するためのコマンドです。そして、最後にnn_model.fit()で学習を開始することができます。今回は、モデルの順伝播->損失関数の計算->逆伝播->重みの更新を1ステップと考えた場合にこれを100回繰り返すことにします。また、実データとの離れ具合を二乗和で表す損失関数Lossと、実データとの離れ具合の絶対値の和で表す平均絶対誤差(MAE)を学習の繰り返し回数とペアーでプロットしたものを示します。
細かいことは省略しますが、値が下がれば下がるほど良いのです。では最後に、学習させたモデルを使ってテストデータを使って、住宅価格の予測値を返してみましょう。
数点テストデータと予測データが若干全体的な特徴は掴んでいると判断して良いでしょう。
最後に演習問題として、余裕があれば以下の問題に取り組んでみましょう。
(1) 上では入力の次元を3次元に限定しました。特徴量の個数を増やしても予測は適切に行えるでしょうか?
(2) モデルの定義は適切でしょうか? 今回は、3層のニューラルネットワークをつくり、隠れ層の特徴量数は64で統一しました。隠れ層の特徴量数を変えてみたり、隠れ層の層数自体を増やしてみるとどのような結果が得られるでしょうか?
(3) 最適化手法において、learning_rate(学習率)を変えてみるとどうなるでしょうか? 学習率が大きすぎると最適なパラメータを通り越してしまい、小さすぎると学習がいつまでたっても終わりません。どのくらいの値が良いか試しながら理解してみましょう。
終わりに
今回は深層学習の入り口となるニューラルネットワークについて解説しました。このネットワークを発展させたモデルが年々開発され、人工知能技術を進歩させてきました。今回紹介した内容をベースに人工知能の分野で用いられている手法について他の記事でも解説を行なっているので、興味のある人はぜひそちらもチェックしてみてください。










