


今回はAIの判断根拠を可視化する手段について紹介します。CNN(畳み込みニューラルネットワーク)が画像の分類を行う際、通常は画像のどの部分をもとに判断をしているかはわかりません。医療画像解析などのミスが許されないタスクにおいては、判断根拠が分からないと信頼性に欠けるという問題があります。そこで、CNNが画像のどの部分に注目して判断しているかを明らかにする技術がCAM(Class Activation Mapping)です。
Contents
CAMとは
CAM(Class Activation Mapping)は、CNNが画像のどの部分に注目しているかを可視化する技術です。通常、CNNは画像全体の特徴を学習し、最終的な分類を行いますが、その判断根拠を直接確認することは困難です。そこで、CAMを用いることで、モデルがどの領域を重要視しているのかを視覚的に理解することができます。下記の画像はResNet(画像解析モデル)において画像を猫と判定した際の各ピクセルに対する注目度をヒートマップで表したものです。赤い領域ほど注目度が高いです。上記の画像からこのモデルは猫の顔とお腹のあたりを重視して判断していることが分かります。

CAMの仕組み
CAMの仕組みを理解してもらうためには、CNNの知識が必要となるためCNNをあまり覚えていない方はこちらで復習してみてください。ここからはCNNを理解している前提でお話します。
CNNのクラススコアの計算方法
CAMは、画像内の各ピクセルが、CNNの予測したクラスに対してどれほど寄与しているかを計算する手法です。そこで、まずはじめにCNNが入力画像に対して、どのようにクラスを予測しているのか、その計算方法を復習します。
下記の画像は想定するCNNとその中間出力である特徴マップを可視化したものです。特徴マップは、CNNの最終畳み込み層の出力であり、マップごとに様々な特徴に注目しています。例えば、左端の特徴マップは元画像の「人」がいる部分が赤くなっており「人」という特徴に注目していることが読み取れます。また、左から2番目の特徴マップは「犬」部分に注目していることがわかります。
これらの各特徴マップは、GAP(Global Average Pooling)によってそれぞれスカラー値に変換されます。GAPでは、各マップの平均値をとり、特徴マップ全体が1つの値に要約されます。その結果、これらの平均値を要素とするベクトルが出力されます。
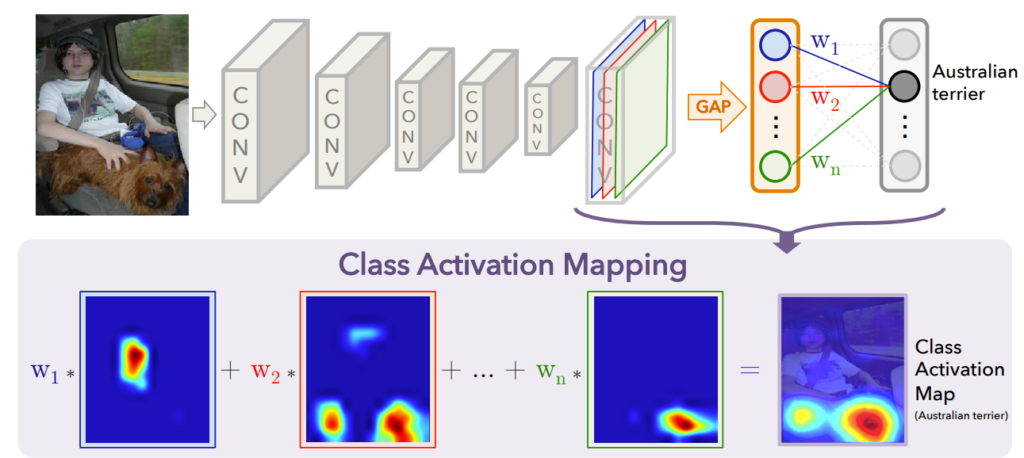
その後、GAPによって得られたベクトルは、全結合層(Fully Connected Layer)に入力されます。この層では、各特徴マップの平均値に対して、対応する重み \(W_i\) を掛けて足し合わせることで、各クラスのスコア(予測値)が計算されます。
CAMの計算方法
CAMの流れとしては、先ほど紹介したCNNの処理の流れを逆算することで各ピクセルのクラスへの寄与の大きさを測定します。具体的には、各ピクセルは「そのピクセルが特徴マップでどれだけ重視されているか」×「その特徴マップが分類にどれほど重要か」の合計スコアで決まります。これらについて説明していきます。
「そのピクセルが特徴マップでどれだけ重視されているか」
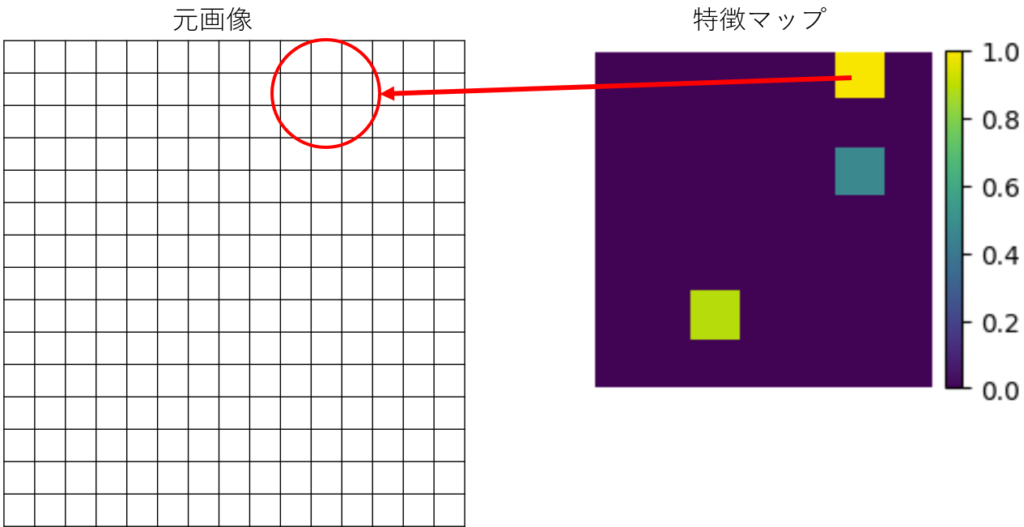
下記は、先ほどの猫の画像を可視化する際に使用された 7×7 の特徴マップ です。
CNNでは、元画像(224×224 など)を畳み込みやプーリングによって小さなマップに圧縮 していきますが、今回の例では結果が 7×7 の形状として表れています。
1 マス(7×7 の各セル) は、元画像上の広い範囲を集約して得られた値です。たとえば (0,0) のマスには、元画像の左上付近の情報が集約されています。特徴マップにおける重要度はマスの値によって判断されます。値が大きいマス は、対応する領域にある複数のピクセルが「その特徴マップのパターンに強く反応している」ことを意味します。つまり、値が大きいマスを形成している元画像のピクセル は、「この特徴マップにおいて特に重要度が高い」といえます。このように逆算することで、各ピクセルが各特徴マップでどれほど重視されているかわかるわけです。

「その特徴マップが分類にどれほど重要か」
各特徴マップが分類においてどれほど重要かは、全結合層で使用される重み\(W_i\) から判断できます。
先に説明したように、CNNが画像のクラスを予測する際には、中間層で得られる各特徴マップをGAP(Global Average Pooling)によって平均化し、それをベクトルとして全結合層に入力します。このとき、各特徴マップの平均値に対応する重みを掛けて足し合わせたものが、各クラスのスコアとして用いられます(下図参照)。
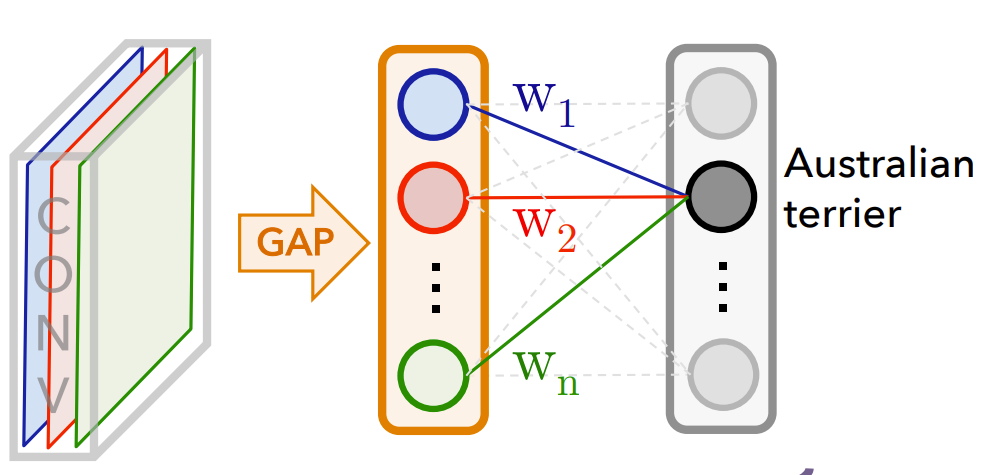
したがって、重みの値\(W_i\) が大きいほど、その特徴マップは分類に対して重要な役割を果たしていると考えられます。
GAPを使用していない場合は、このように重みと特徴マップを対応づけることができないため、基本的にCAMを利用できません。
「そのピクセルが特徴マップでどれだけ重視されているか」×「その特徴マップが分類にどれほど重要か」
上記の内容をまとめると、各ピクセルの重要度は、特徴マップにおける値の大きさと各特徴マップのGAP(Global Average Pooling)における重みを掛け合わせたものです。このようにして各ピクセルの重要度を可視化するわけです。
やってみよう
下記はCAMのコードです。今回はコードの細かい仕様は説明しませんがさきほど説明した内容をコードにしたものです。
import numpy as np
import tensorflow as tf
import cv2
import matplotlib.pyplot as plt
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions
# 1. ResNet50 (ImageNet学習済み) をロード
base_model = ResNet50(weights="imagenet", include_top=True)
# ResNet50 の最終畳み込み層は "conv5_block3_out"
last_conv_layer_name = "conv5_block3_out"
last_conv_layer = base_model.get_layer(last_conv_layer_name)
# 2. 最終畳み込み層の出力を取得するサブモデル
sub_model = tf.keras.Model(inputs=base_model.inputs, outputs=last_conv_layer.output)
# 3. 画像を読み込んで前処理する関数
def preprocess_image(image_path, target_size=(224,224)):
img = cv2.imread(image_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, target_size)
img = np.expand_dims(img.astype(np.float32), axis=0)
img = preprocess_input(img)
return img
# 4. CAMを計算する関数
def compute_cam(model, sub_model, image_path, class_index):
preprocessed_img = preprocess_image(image_path)
conv_output = sub_model(preprocessed_img)[0] # shape=(7,7,2048)
preds = model(preprocessed_img) # shape=(1,1000)
final_dense = model.get_layer("predictions")
final_w = final_dense.weights[0].numpy() # shape=(2048,1000)
weights_for_class = final_w[:, class_index]
cam = np.dot(conv_output, weights_for_class)
ReLU & 正規化
cam = np.maximum(cam, 0) # ReLU
cam = (cam - np.min(cam)) / (np.max(cam) - np.min(cam) + 1e-8) # 正規化
return cam
# 5. CAMを元画像に重ね合わせる関数
def overlay_cam(image_path, cam, alpha=0.4):
raw_img = cv2.imread(image_path)
raw_img = cv2.cvtColor(raw_img, cv2.COLOR_BGR2RGB)
H, W, _ = raw_img.shape
cam_resized = cv2.resize(cam, (W, H))
cam_resized = (cam_resized * 255).astype(np.uint8)
# ★ 修正: カラーマップ反転(必要なら適用)
cam_resized = 255 - cam_resized # 逆転する場合
cam_color = cv2.applyColorMap(cam_resized, cv2.COLORMAP_JET)
overlay_img = cv2.addWeighted(raw_img, 1 - alpha, cam_color, alpha, 0)
return raw_img, overlay_img
# 6. 実行例
if __name__ == "__main__":
image_path = '' # 適切な画像を設定
input_img = preprocess_image(image_path)
preds = base_model.predict(input_img)
decoded = decode_predictions(preds, top=5)
print("Top-5 Predictions:")
for (imagenet_id, label_name, score) in decoded[0]:
print(f" {imagenet_id} : {label_name} (score={score:.4f})")
top_index = np.argmax(preds[0])
print("\nTop-1 predicted class index:", top_index, " | Score:", preds[0][top_index])
cam = compute_cam(base_model, sub_model, image_path, class_index=top_index)
raw_img, cam_img = overlay_cam(image_path, cam, alpha=0.5)
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
plt.imshow(raw_img)
plt.title("Original Image")
plt.axis("off")
plt.subplot(1,2,2)
plt.imshow(cam_img)
plt.title("Class Activation Map")
plt.axis("off")
plt.show()
まとめ
今回はCNNの判断根拠の可視化技術であるCAM(Class Activation Mapping)について解説しました。CAMは、現在ある様々な可視化技術のパイオニア的存在です。CAMを理解することはその他の可視化技術の理解に役立つと思いますので是非覚えてみてください。










