


本記事ではTensorFlowの基本的な使い方について簡単なデータセットを用いて体験してもらいます。これからTensorFlowについて学ぼうされていた方や改めて基本的なAPIの使い方を学び直したいという方が対象です。そのため、すでにTensorFlowを習熟されている方にとっては知っていることが多い場合もあるのでご了承ください。
本記事の構成は下記の通りです。それではTensorFlowの世界に足を踏み入れてみましょう!!
Contents
TensorFlowとは
TensorFlowは、Googleが機械学習向けに開発したオープンソースのプラットフォームです。様々なツールやライブラリ、コミュニティリソースを有しており、大規模な機械学習プロジェクトに適しています。TensorFlowのライブラリを使用すれば深層学習モデルを容易に構築することが可能です。ぜひ使いこなせるようになりましょう。
テンソル
まず、TensorFlowにおける基本的なデータ構造であるテンソル(tensor)について説明します。TensorFlowにおけるtensorとは多次元配列のことです。Pythonにおける多次元配列ライブラリと言えばNumPyが有名ですが、TensorFlowにおけるtensorは深層学習用に最適化されています。TensorFlowでは、このtensorがあるオペレーションから次のオペレーションへと流れて(flow)いくため、TensorFlowという名前が付けられているようです。
それでは、簡単なtensor型データを作成してみましょう。tensorflowのconstant()メソッドでtensorを作成することができます。
TensorFlowのtensor(tf.Tensor)にはint32やfloat32など、様々な型のデータを渡すことができます。上のコードではfloat32型のデータを渡しています。tf.TensorはNumPyのndarrayと似ており、様々な多次元配列演算を行うこともできます。
なお、このtf.constant()は定数を定義するためのメソッドです。変数を定義したい場合はtf.Variable()メソッドを用います。TensorFlowの高レベルAPIであるKerasのパラメータは一般的にこのtf.Variable型であり、tensor同士の計算を行うときはtf.Varable型のデータを用いるのが推奨されます。
また、tf.TensorはNumPyのndarrayとの互換性があり、ndarrayからtensorへ変換することも、逆にtensorからndarrayへ変換することもできます。
TensorFlowのtensorに関する基本的な説明は以上になります。
TensorFlowを用いたXORゲートの実装(Sequential API)
ここまでの内容は少し退屈だったかもしれませんが、ここからはTensorFlowを用いて簡単なニューラルネットワークモデルを作成していくので楽しくなってくると思います。今回はニューラルネットワークに学習させて、XORゲートを実装することを目指します。XORゲートは論理回路の一つで、入力と出力の表は以下のようになっています。
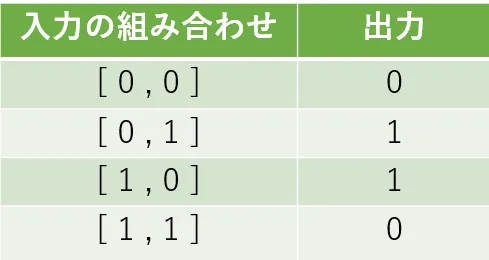
表をよく見ると、入力値を「0を出力させるもの」と「1を出力させるもの」に分けることができるとわかります。0を出力させるものは[0, 0]と[1, 1]で、1を出力させるものは[0, 1]と[1, 0]です。入力の組み合わせを[x1, x2]に対応させて横軸をx1、縦軸をx2として図示すると以下のようになります。
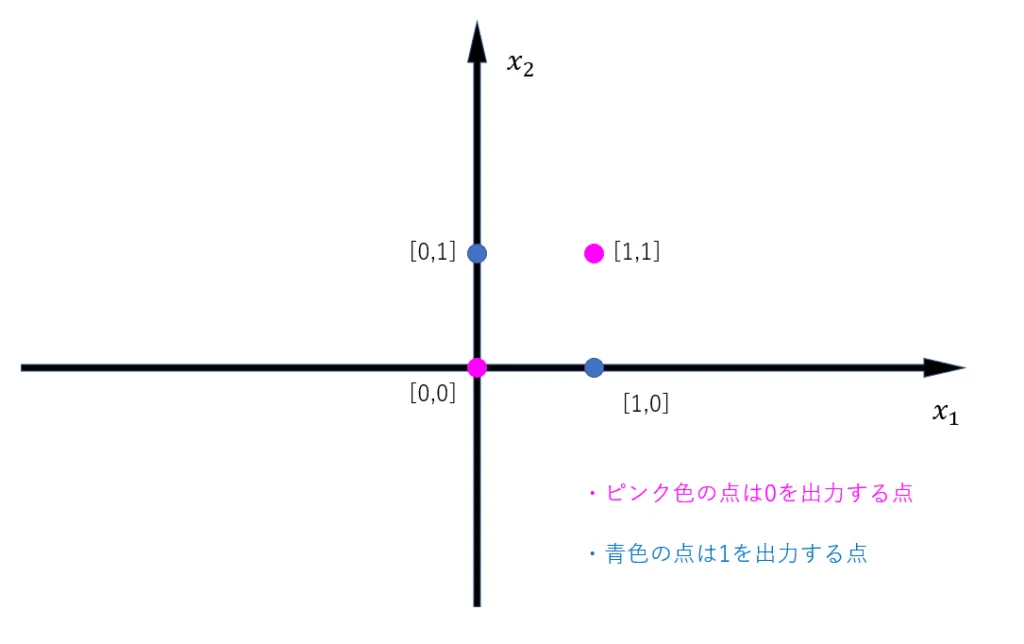
このデータは以下の図を見てわかる通り一本の直線では分離できず、曲線でなら分離できます。
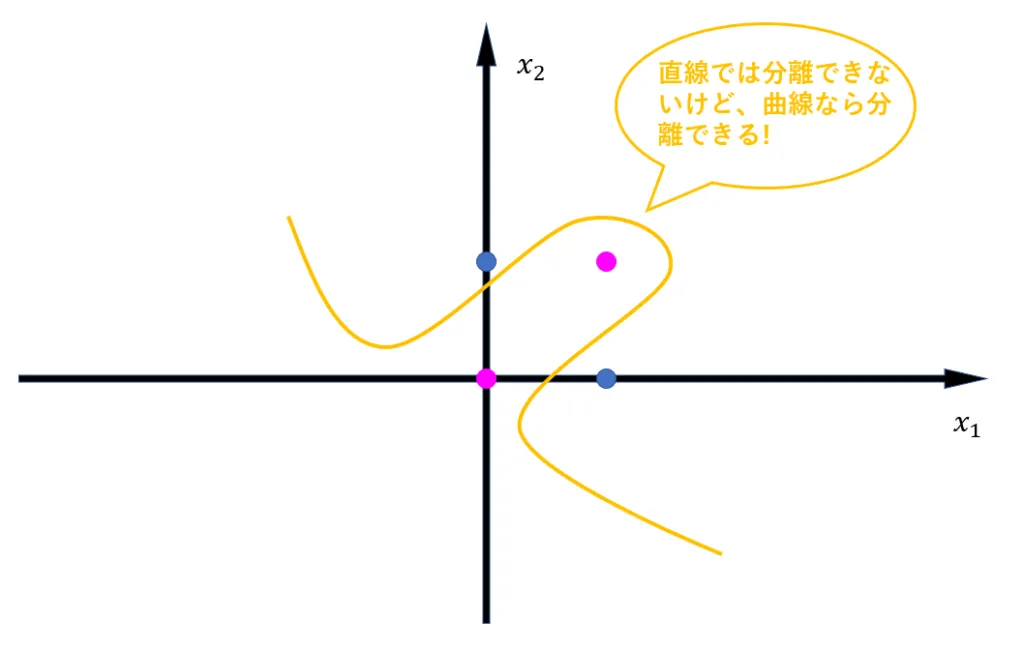
よってXORゲートを構築するということはすなわち、非線形モデルを構築するということになります。ニューラルネットワークを用いれば、このような非線形モデルは容易に構築することが可能です。それでは実際にニューラルネットワークモデルを作成し、学習させることでXORゲートを実装していきましょう。
モデルの構築
まず、モデルの構築方法について説明します。
TensorFlowにはモデルの定義の仕方が3つ存在します。Sequential API、Functional API、Subclassing APIです。Sequentail APIではモデルの構築から学習まで非常に簡単に実装することができます。Functional APIで書く場合はSequential APIに比べてより柔軟な、自由度の高いモデルを構築できます。Sequential APIによる書き方とFunctional APIによる書き方とでは、それほど大きな違いがありません。Subclassing APIはこれらよりモデルのカスタマイズの幅が広く3つの書き方の中では最も自由度が高いですが、玄人向けです。
Sequential APIは初学者向けの方法なので、今回はまずSequential APIでの書き方について説明します。
Sequential APIで書く場合はSequentialオブジェクトを生成した後、そこにSequentialクラスのadd()メソッドで層を追加していくことでモデルを構築するという流れになります。実際に簡単なモデルを作成してみましょう。
ここでは入力のサイズが2で出力のサイズが2、活性化関数はsigmoid関数という一層だけの簡単なニューラルネットワークモデルを作成しました。TensorFlowのDense層は線形変換を行いますが、活性化関数を指定することで線形変換の後に非線形変換も行えます。モデルのサマリを見てみるとTotal paramsは6、すなわちパラメータ数は全部で6個と表示されています。これは下の図のように、入力サイズ2の線形変換二つ分だからです。青丸で囲んでいるのがパラメータに該当し、 \( x_1,x_2 \) は入力、 \( y_1,y_2 \) は出力を表しています。
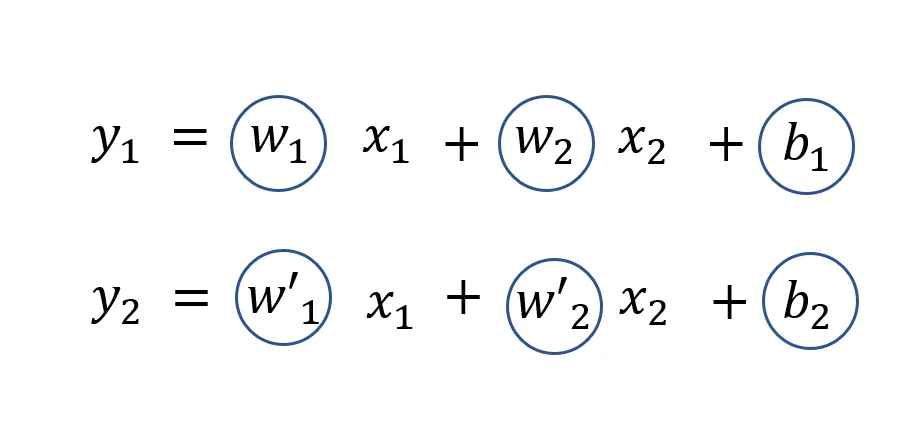
では、今回実装するXORゲート用のモデルを定義します。XORゲートは一層だけで実装するのは難しいので、層を増やしてモデルの表現能力を向上させてあげる必要があります。以下のモデルの一層目では、入力の特徴量二つから八つの特徴量を生成しています。このような、中間の層(隠れ層)における特徴量を隠れ特徴量などと呼びます。
このモデルを図で表すと以下のようになります。
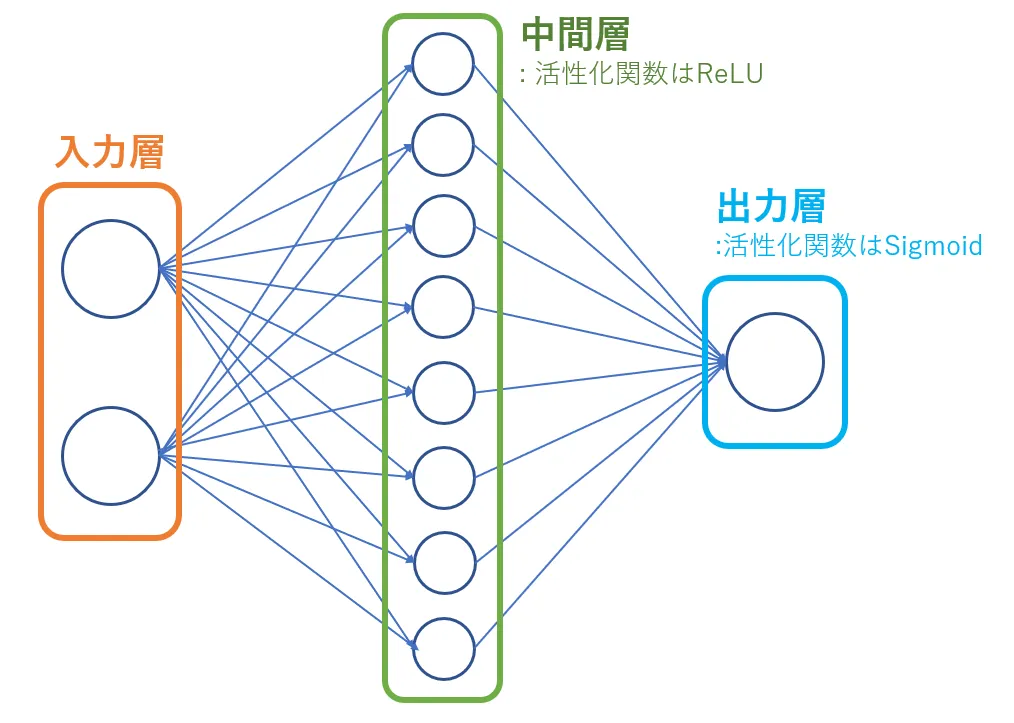
入力層が二つのニューロン、中間層が8つのニューロン、出力層が1つのニューロンから構成されています。これでモデルを定義することができました。
モデルのコンパイル
ここまでで我々はモデルを定義できましたがこれだけではまだ不十分で、Sequential APIではモデルをコンパイルしてあげる必要があります。Sequential APIではコンパイルという処理を行うことで様々な処理が設定されたモデルが構築されるようになっているため、Sequential APIでモデルを構築する場合は必ずコンパイルを行わなければいけません。また、このコンパイルする段階で深層学習において重要な要素である損失関数、オプティマイザを定義します。コンパイルする前に、まず損失関数、オプティマイザについて見ていきましょう。
損失関数
損失関数は、モデルによって予測された値と実際に測定された値(真の値)とを比較し、その誤差(損失)を数値として返します。この損失が小さいほどモデルの性能が良いということなので、重みやバイアスなどのパラメータはこの損失を小さくするように更新していきます。
損失関数には様々なものがありますが、平均二乗誤差(MSE)や交差エントロピー損失(BCE、Binary Cross Entropy)などが有名です。今回は交差エントロピー損失(BCE)を用いてみます。交差エントロピー損失は式で表すと非常に難しく数学的な知識が必要とされますが、実はTensorFlowには損失関数があらかじめいくつか備わっています。損失関数はコンパイルする段階で指定することになります。
パラメータ更新(勾配降下法、オプティマイザ)
損失関数によって誤差を計算した後、その誤差を用いてパラメータを更新します。よって損失関数が最小になるようにパラメータを更新していくことになりますが、そこでは勾配降下法と呼ばれる手法がよく使われます。例えば、損失関数が以下のような簡単な2次関数(縦軸は損失、横軸はパラメータ)だった場合を考えてみます。
この損失関数の最小値はグラフからもわかる通り、パラメータ軸が0のときで、0です。以下の図の赤い点を考えたとき、その点における損失はまだ最小ではありません。
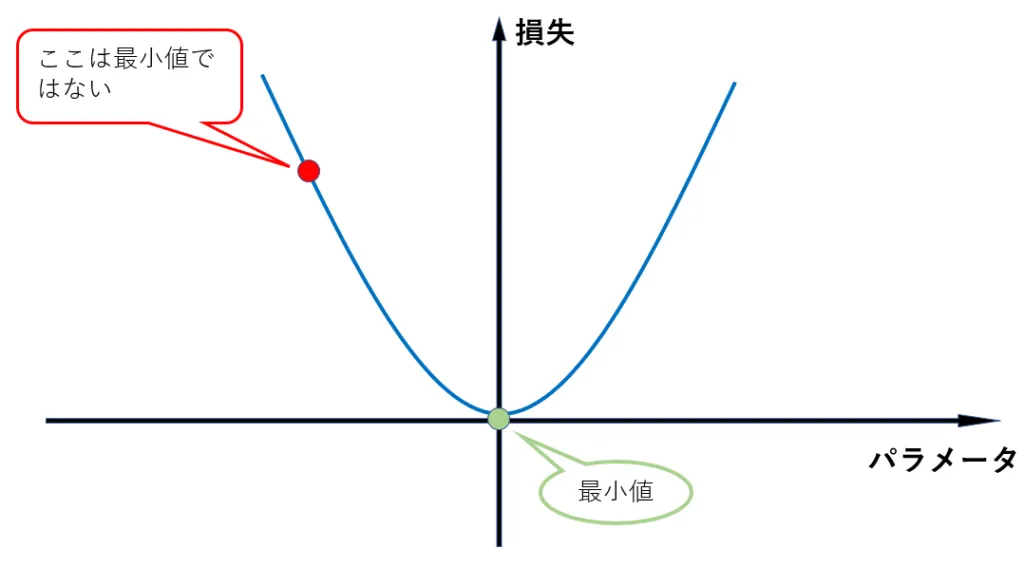
そこで、その点における勾配(傾き)を計算し、パラメータを更新することで、その勾配に沿ってより小さい方へ点を動かします。
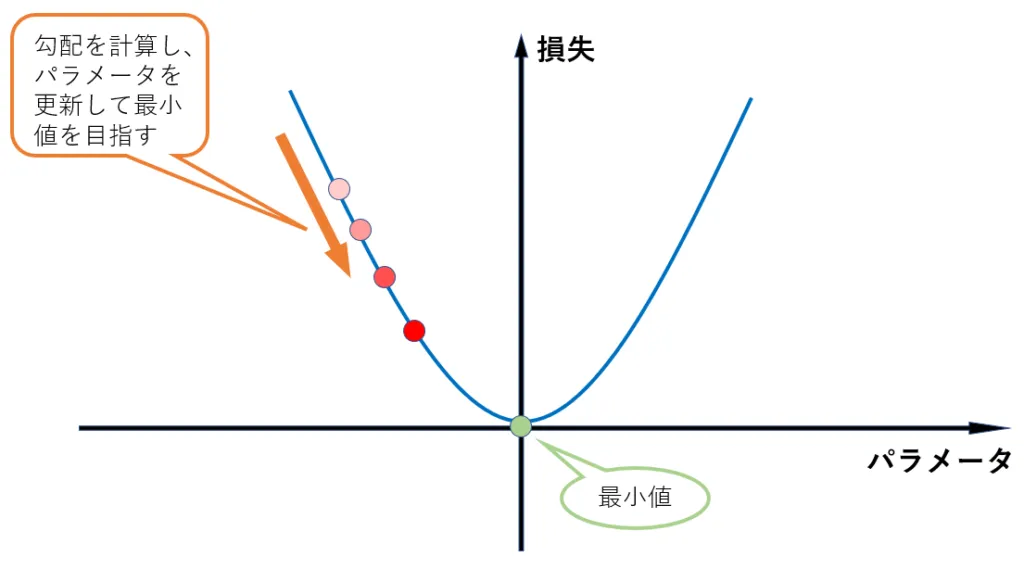
この更新を、縦軸の損失を \( L \) 、横軸のパラメータを \( p \) 、学習率を \( \alpha \) とし、式で表すと以下のようになります。勾配の計算は、数学的には微分という手法を用いています。また、学習率 \( \alpha \) は更新の度合いを調整するハイパーパラメータです(ハイパーパラメータとは、モデルが学習を通して調整するのではなく人間が調整するパラメータのことです)。
これを繰り返すことで、最終的には勾配が0の点、すなわち最小値にたどり着くことができます。ボールが坂を転がっていき、最終的には平坦な場所で止まることを想像してもらえるとなんとなく理解できるかと思います。このように、勾配を計算し、損失が小さくなるようにパラメータを更新していく手法を勾配降下法と呼びます。
なお、この勾配はモデルの出力側から入力側に向かって、各パラメータについて計算されます。こうすることで、モデルの全てのパラメータを更新することが可能となります。このように、出力側から入力側へ、逆向きに損失の勾配を計算していく手法を誤差逆伝播法と呼びます。
実は、TensorFlowには誤差逆伝播法で勾配を自動で計算する仕組みが備わっています。Sequential APIでは、パラメータ更新や誤差逆伝播法について意識しなくても後に示すようにKerasのメソッドを実行するだけで簡単にそれらを実行することができてしまいます。
勾配が求まると後は勾配降下法でパラメータを更新するだけだと思いきや、実はこの勾配降下法には弱点があります。もしも損失関数が以下の図のような関数だったらどうでしょうか。
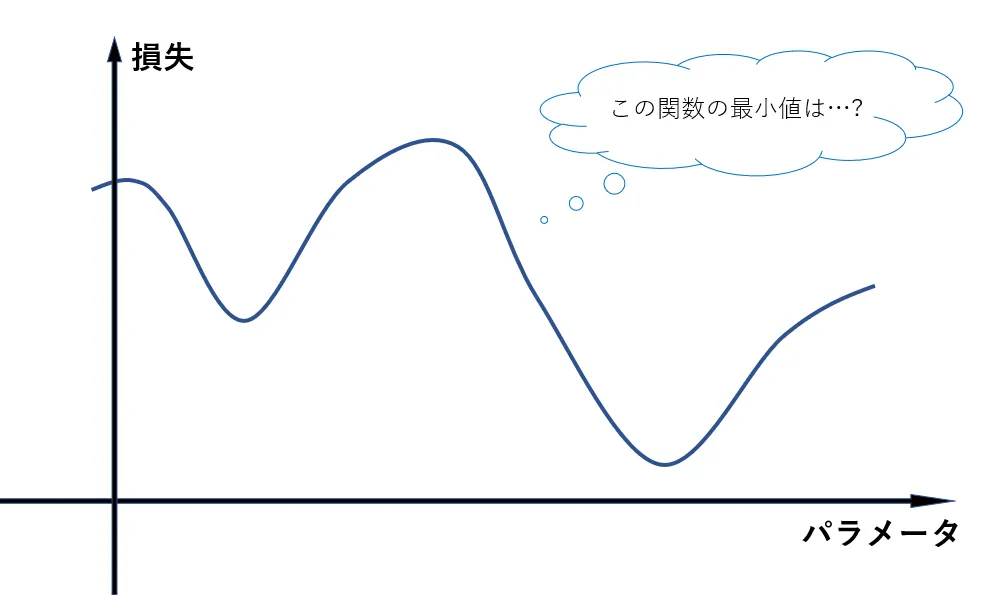
この図のような場合、下の図におけるピンク色の点を最小値だと勘違いしてしまうかもしれません。しかし、見てわかる通り実際の最小値とは異なっています。
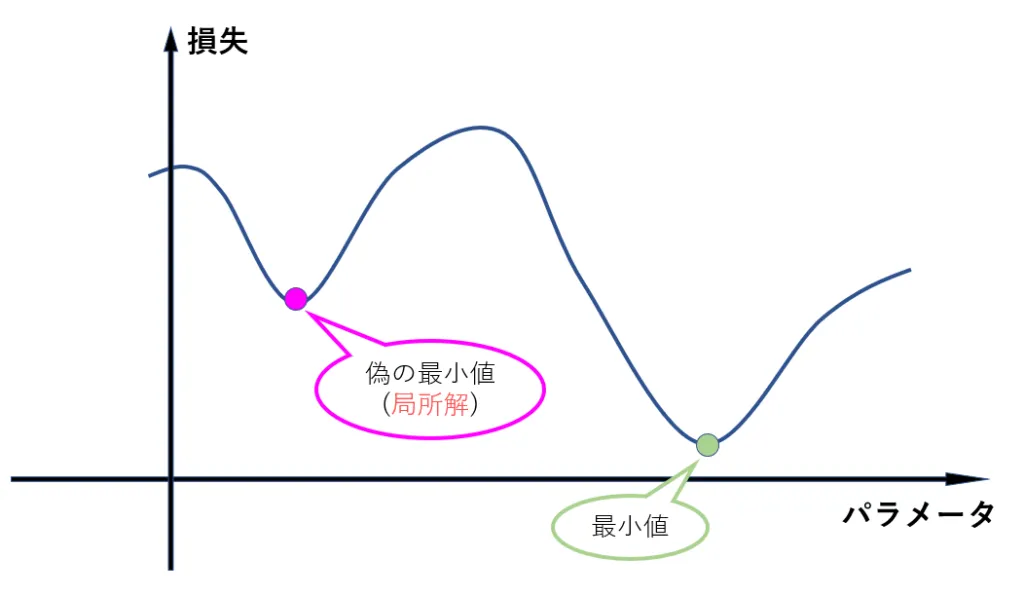
このような偽物の最小値を「局所解」といいます。局所解に陥ると、勾配降下法ではそこを最小値と判定してそれ以上パラメータを更新しなくなってしまいます。ボールが坂を転がっていく途中でくぼみにはまってうごけなくなってしまうイメージです。これは、勾配降下法が勾配が0になるのを目指してパラメータを更新するアルゴリズムであるために発生する問題です。
そこでTensorFlowには、このような局所解に陥るのを防ぐことができるパラメータ更新アルゴリズムを選ぶことができる機能が備わっています。この、パラメータをどのように更新するかを決めるものをオプティマイザと言います。TensorFlowにおけるSequential APIでの書き方では、コンパイルする段階で使用するオプティマイザを指定することになります。
ここまでで、コンパイル時に指定する損失関数、オプティマイザについてはある程度理解できたのではないかと思いますので、実際にモデルのコンパイルを実装してみましょう。実装は簡単で、Sequentialクラスによって生成されたmodelのcompile()メソッドを実行するだけです。この際、compile()メソッドの引数にはオプティマイザ、損失関数を指定します。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD #インポートを忘れずに
model = Sequential()
model.add(Dense(input_dim = 2, units = 8, activation = 'relu'))
model.add(Dense(units = 1,activation = 'sigmoid'))
#モデルのコンパイル(引数にオプティマイザ、損失関数を指定)
model.compile(optimizer = SGD(lr = 0.5), loss = 'binary_crossentropy')モデルに学習させる
ここまでで、学習に必要なモデルの要素は全て揃いました。あとはデータを用意し、実際にモデルに学習させるコードを実装するだけです。
一般的な深層学習の流れは、
- 訓練用データ、試験用データを用意
- モデルを用意
- モデルに訓練用データで学習させる
- 試験用データで推論
となります。これに沿って進めていきます。
では、まず訓練用データと試験用データを用意します。今回はXORゲートと同じ機能になるように学習させたいので、訓練用データは以下の表と同じデータを用意します。
すなわち、
import numpy as np
X = np.array([[0 , 0],[0 , 1],[1 , 0],[1 , 1]] )#データ
y = np.array([[0],[1],[1],[0]])#ラベルとなります。Xは入力データで、yはその各データに対応するラベル(出力値)です。
ところで、データは学習に用いる訓練用データの他にモデルの精度を評価するための試験用データも用意するのが一般的です。なぜなら、モデルには汎化性(新しいデータに対して高い精度を出すこと)が求められるからです。学習に用いた訓練用データに対し高い精度が出せるのはほとんど当たり前と言ってよく、学習に用いてない新しいデータに対しても高い精度を出せるかが重要です。
しかし今回の目的はXORゲートを実装することなので特に試験用データは用意せず、推論では学習させたモデルに [ 0 , 0 ] , [ 0 , 1 ] , [ 1 , 0 ] , [ 1 , 1 ]を代入してみて、それぞれに対応する出力が得られるかを確認することにします。
次に、モデルを用意します。今までに説明してきた通りです。
では、これまでのまとめをかねて、いよいよモデルに訓練させます。モデルにデータを入力し、損失を計算し、パラメータを更新する一連の流れをエポックと呼びます。今回は1000エポックほど学習させます。Sequential APIで作成したモデルでは、fit()メソッドでデータ、ラベル、エポック数を指定して実行するだけで訓練させることができてしまいます。
ついでに損失の下がっている様子を描画してみましょう。fit()メソッドはtf.keras.callbacks.Historyオブジェクトを返します。このオブジェクトのhistory属性には訓練結果の辞書型データが格納されているため、辞書のキーを指定してmatplotlibで容易に描画できます。
import matplotlib.pyplot as plt
#描画
plt.plot(history.history['loss']) #fit()メソッドの出力に保存されている損失を描画
plt.show()では、学習させ、その結果を描画してみましょう。
fit()メソッドでは、エポック毎にかかった時間とloss(損失)の値が自動で表示されるようになっていますが、出力が長くなるため今回はverbose = 0を指定して非表示にしています。しかし図を見てみると、lossはエポック毎に下がっていっているのがわかります。損失が少なくなるように学習させているので、これは上手く学習が進んでいるということです。
では、学習が完了したので推論をさせてみましょう。学習後のモデルに[ 0 , 0 ] , [ 0 , 1 ] , [ 1 , 0 ] , [ 1 , 1 ]という組み合わせを代入します。Sequential APIで構築したモデルに推論させる際は、以下のようにpredict()メソッドを実行します。
import numpy as np
np.set_printoptions(suppress = True)#指数表記を禁止
#推論
pred = model.predict(X) #predictメソッドを実行得られた出力をXORゲートの出力と見比べてみましょう。
見比べてみると、確かにほぼ同じ値が出力されているのがわかります。上手くモデルに学習させ、XORゲートを実装することができたようです。以上が、Sequential APIでのディープラーニングの実装になります。
TensorFlowを用いたXORゲートの実装(Subcrassing API)
ここまででだいぶ疲れたと思いますが、もう少しだけお付き合いください。Sequential APIでXORゲートを実装しましたが、これをSubclassing APIで実装してみましょう。
Subclassing APIではモデルの定義の仕方がSequential APIとは全く異なる上、コンパイルを行わないという違いもあります(Sequential APIと同じようにコンパイルしてもできるようですが、今回は勉強のためにコンパイルしない方法で実装します)。では、Sequential APIのときと同じ流れで実装していきましょう。
モデルの構築
Subclassing APIでは、モデルをクラスとして定義します。
import tensorflow as tf
class Net(tf.keras.Model): #tf.keras.Modelを継承したクラスとして作成
def __init__(self,input_dim, hidden_dim, output_dim): #コンストラクタで入力層、隠れ層、出力層のサイズを指定
super(Net,self).__init__()
self.f1 = tf.keras.layers.Dense( #一層目
units = hidden_dim, #隠れ層のサイズ
input_dim = input_dim, #入力層のサイズ
activation = 'relu' #活性化関数はReLU
)
self.f2 = tf.keras.layers.Dense( #二層目(出力層)
units = output_dim, #出力層のサイズ
activation = 'sigmoid' #活性化関数はSigmoid
)
#順伝搬処理
def call(self, x, training = None):
x = self.f1(x)
y = self.f2(x)
return y
#モデルをNetクラスのインスタンスとして生成
net = Net(2, 8, 1)
モデルをクラスとして定義する際は、tf.keras.Modelを継承したクラスとして作成しなければならないことに注意してください。また、上のコードのように、コンストラクタのinit()メソッドにおいてニューラルネットワークの層を定義し、それをcallメソッドで呼び出して用います。
損失関数
続いて、損失関数の定義です。用いる損失関数自体は変更しませんが、Subclassing APIではコンパイルを行わないため、オブジェクトとして定義する形になります。ここではKerasに用意されている損失関数の中からBinaryCrossEntropyを用います。
from tensorflow.keras.losses import BinaryCrossentropy
loss_fn = BinaryCrossentropy()パラメータ更新(勾配降下法、オプティマイザ)
さらに、オプティマイザもオブジェクトとして定義します。ここでもオプティマイザの種類に変更はなく、Kerasに用意されているオプティマイザの中からSGDを用います。
from tensorflow.keras.optimizers import SGD
optimizer = SGD(learning_rate = 0.5) #引数には学習率を設定モデルに学習させる
Subclassing APIでは、パラメータ更新を行う関数も用意してあげる必要があります。Sequential APIのときはコンパイルして訓練ループを回すだけでよかったのに対し、なかなか面倒です。この関数内で行う処理は、「順伝搬の出力値を取得」、「出力とラベルの誤差(損失)を取得」、「誤差に基づいてパラメータを更新」です。ここではTensorFlowのGradientTapeクラスを用います。GradientTapeには勾配を計算するための機能が備わっています。
def train(x,t):#データとラベルを受け取る
with tf.GradientTape() as tape: #GradientTape()は勾配の記録機能
pred = net(x) #順伝搬
loss = loss_fn(t,pred) #損失計算
grad = tape.gradient( #gradientメソッドに損失、パラメータを渡すことで勾配を計算して記録
loss,
net.trainable_variables #モデルの更新可能なパラメータを渡しておく必要がある
)
optimizer.apply_gradients(zip(grad, net.trainable_variables))#勾配を利用してパラメータを更新
return loss #損失が下がっているかを確認するために損失の値を返す上のコードを見ると、構築したモデルのインスタンスを順伝搬処理で用いているのがわかります。モデルの出力、損失を計算した後、それらをtf.GradientTapeオブジェクトに記録し、tf.GradientTapeのgradient()メソッドにより損失から勾配を計算します。その後、計算した勾配を用いてoptimizerのapply_grdientsメソッドでパラメータを更新します。
GradientTapeの勾配計算機能は少し複雑です。例えば下のコードでは、x, w, bというtensorを用意し、f = w * x + b という式をwについて微分してf = w * x + bのwに対する勾配を計算しています。このように、GradientTapeのgradientメソッドの引数に式と変数を渡すと、その変数についての勾配を計算してくれます。
2つ上のコードで作成したtrain関数の中ではGradientTapeのgradientメソッドに損失関数とモデルのパラメータを渡しています。行っている処理自体は一つ上のコードでgradientメソッドにfとwを渡したときと同じです。 この勾配計算の仕組みが難しいため、初学者の方はSequential APIで書くのがよいかもしれません。
では、パラメータ更新を行う関数が定義できたので学習させましょう。1000エポック学習させます。また、損失の下がっている様子も描画してみましょう。今回はfit()メソッドを用いていないため、損失をリストに格納して描画する形になります。
lossはいい具合に下がっています。推論させてみましょう。
上手く学習できているようです。モデルの構造、エポック数、損失関数、オプティマイザはSequential APIのときと全く同じなので推論結果もほぼ同じになります。
まとめ
本記事ではTensorFlowの基礎的な使い方についておおまかに説明しました。今回説明したことは
- TensorFlowの基本的なデータ構造であるテンソル
- ディープラーニングの重要な要素
- Sequential APIによる簡単なディープラーニングの実装
- Subclassing APIによる簡単なディープラーニングの実装
など、重要なものばかりです。内容も非常に多かったのではないかと思うので、よく復習しておくとよいでしょう。
TensorFlow チュートリアル Part2 を公開!
本記事の続編を公開しました!!複雑になったデータを分類するニューラルネットワークの威力を体験できると思います。また、新たなテクニックも紹介しているのでぜひ見てもらえると嬉しいです。
参考文献
- チーム・カルポ 『物体・画像認識と時系列データ処理入門』. 2021
- TensorFlow API v2.8.0 https://www.tensorflow.org/api_docs/python/tf?hl=ja










