

GPT
GPTとは?
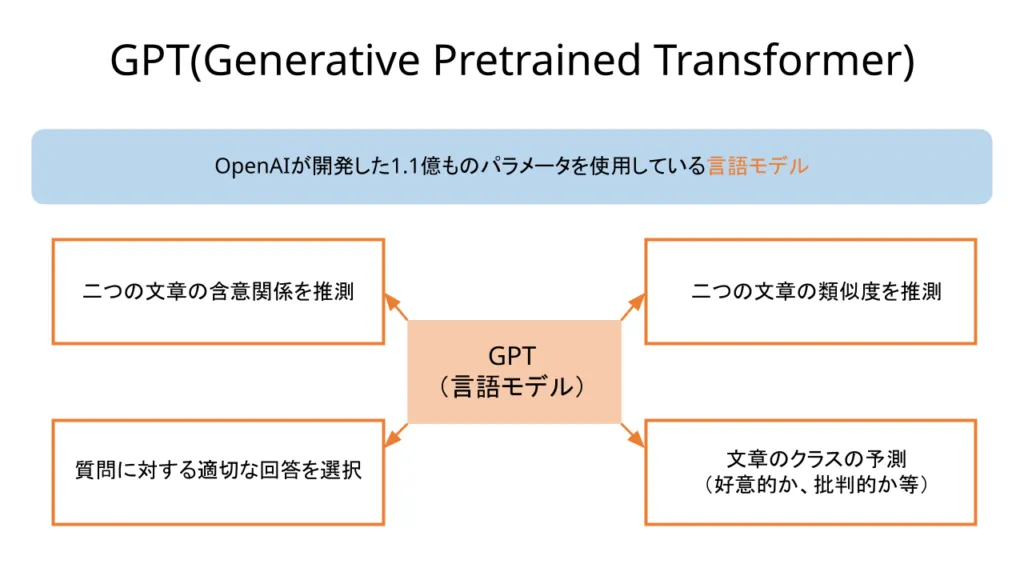
GPT(Generative Pretrained Transformer)とは、米国サンフランシスコの新興人工知能研究所であるOpenAIが開発し、人間のように自然な文章を生成することができる言語モデルです。1億1700万個のパラメータを持つ初期モデルのGPT-1が2018年6月にリリースされて以来、GPT-2, GPT-3, GPT-4など複数のバージョンが発表されています。
[参考] Transformerとは?
GPTは、Transformerと呼ばれるニューラルネットワーク構造を使用しているモデルなので、まずはTransformerの仕組みについてイメージを掴んでおきましょう。
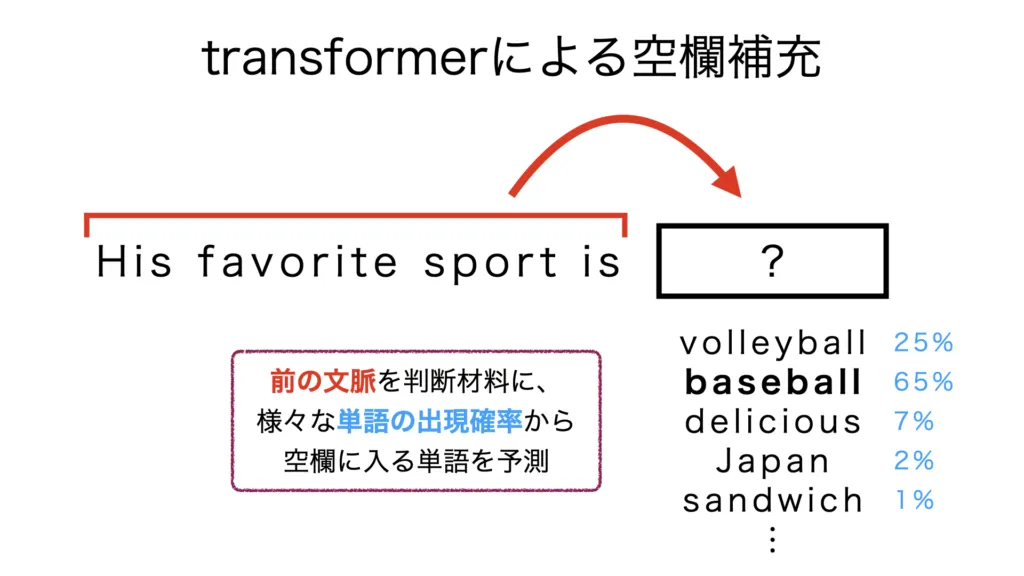
上のイメージ図のように、Transformerにできることは、文章の空欄に入る単語を予測することです。この際、空欄より前の文脈を考慮し、空欄にはどのような単語がどれくらいの確率で入るかを予測します。上の例では、出現確率が65%と最も高い「baseball」という単語が、空欄に入る単語の最終的な予測として出力されるのです。
また、このような空欄補充のタスクを行うためには、その言語の文法や単語の意味をTransformerが事前に学習している必要がありますよね。その学習の際の重要なポイントについて、以下で簡単に説明します。

まずは、①Word Embeddingについてです。”baseball”や”use”といった各単語は、それぞれ特有の意味や品詞的役割を持ちます。これらを機械に理解できる形で表現するため、Transformerでは単語を数値で置き換えます。
②Positionについてですが、これは、それぞれの単語が文章の中のどの位置で登場するか(絶対的位置)と、他の単語との位置関係(相対的位置)の情報です。例えば、”bat”という単語には、「コウモリ」「(野球などの)バット」「破る、大破する」など様々な意味がありますが、上の2つの例文では”baseball”という単語の後ろに来ていることから、「(野球の)バット」の意で使われていると解ります。このようにTransformerでは、単語の位置も非常に重要な情報として考慮します。
③Attentionは、注目するべき単語のことです。上の2つの文において、”he”という指示代名詞が登場する位置が似通っていますが、その指し示す内容は異なります。1つ目の文では、”he”は”Dave”を指し、2つ目の文では、”he”は”his son”を指しますよね。文章の文法的構造を理解するには、単語の絶対的・相対的位置のみでは不十分なため、注目するべき単語の情報も学習する必要があるわけです。
Transformerの具体的な仕組みについては割愛しますが、
- 1. 単語を意味に基づいて数値で置き換え、
- 2. 単語の位置情報を考慮しながら、
- 3. 文法を学習していく
モデルだということを頭の片隅に入れておきましょう。
以下では、Transformerを用いたGPTについて実際に見ていきます。
GPTの仕組みは?
以下は、GPTの構造の模式図と、主な特徴です。

[画像] Alec Radford,Karthik Narasimhan,Tim Salimans,Ilya Sutskever 2018 Improving Language Understanding by Generative Pre-Training より引用
- TransformerのDecoderをベースにしたモデルである。
- 埋め込み層、12層のTransformer Decoder、出力層からなる。
- BookCorpusと呼ばれる非常に大規模なテキストデータのコーパスで事前学習を行う。
- ファインチューニングによって、文章の生成・要約・翻訳を始めあらゆるタスクに活用できます。
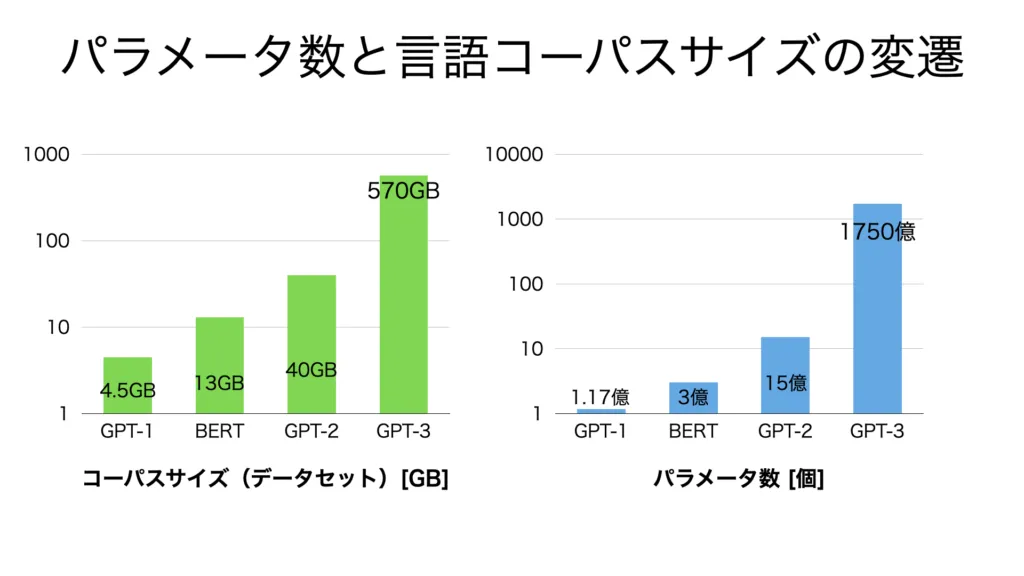
- バージョン(GPT-1, GPT-2 など)によってパラメータ数が異なる。(下図参照)
GPTをより深く理解するために、そのベースになっているTransformerの仕組みや、同じくTransformerをベースにしたモデルであるBERT(Bidirectional Encoder Representations from Transformer)についても学習してみましょう。
GPTは何ができる?BERTとの違いは?
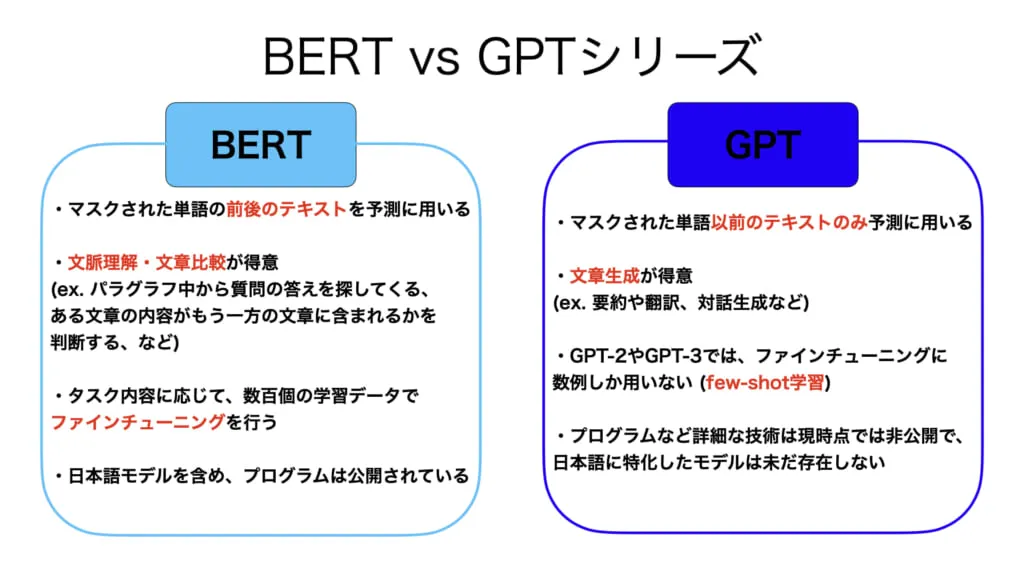
GPTはTransformerをベースにした言語モデルという点でBERTと似ているような気がしますが、それぞれの仕組みと得意なタスクには、以下のような違いがあります。
今話題沸騰中の”ChatGPT”とは?何がすごいの?
ChatGPTとは
2022年11月にOpenAIによって公開されたChatGPTは、非常に高度なAI技術によって、人間のような自然な対話をすることができる無料のAIチャットWEBサービスです。あらゆる質問に対して瞬時に生成される応答のクオリティの高さや人間らしさがたちまち話題となり、5日間という驚異のスピードでその全世界ユーザー数は100万人に達し、リリースから2ヶ月ほどでその数は1億人を突破しています。ユーザー数の100万人到達まで数ヶ月を要したInstagramやSpotifyといったその他の主要サービスと比較しても、ChatGPTの注目度がいかに高いかが伺えるでしょう。
ChatGPTにできること
ChatGPTはGPT-3をベースにしたモデルで、インターネット上にあるあらゆる情報を学習しています。そのため、歴史上の出来事や有名人のプロフィールに関するシンプルな質問への回答はもちろん、人間でも時間を要する複雑なタスクをも驚くべき完成度で推敲できます。以下に例をいくつか挙げます。
👉より体系的に学びたい方は「人工知能基礎」(東京大学松尾豊先生監修)へ
ChatGPTの課題・注意点
ChatGPTは、思わず本当に人間と対話しているような気になるほど自然な応答をしますが、その内容は現時点では必ずしも正確ではないという点には注意が必要です。これは、ChatGPTは過去にインターネット上に存在した情報を学習しているという事実に大きく影響されるでしょう。インターネット上には虚偽の情報も数多く存在する上、ChatGPTは、事実かどうかよりも単語の相互関係や出現確率を考慮して文章を生成します。よって、インターネット上にまだデータが少ない新しい情報の場合などは特に、生成された回答の内容が事実なのかどうかを確認することは重要です。
ですが、現在も開発は続いているので、今後益々精度が上がっていくことは期待できるでしょう。ChatGPTの実際の使い心地や精度が気になる方は、OpenAIの公式サイトでアカウントを作成し実際に使用してみましょう。
ChatGPTの商業利用例
ChatGPTの高いパフォーマンスは、人間の行うタスクを大幅に削減するポテンシャルがあるため、すでに事業活用されているケースがあります。以下に、その例を2つ紹介します。
非上場企業の事業内容の要約(QFINDR)
クレジット・プライシング・コーポレーション株式会社は、ChatGPTを利用して非上場企業の事業内容を集積・要約し、それを検索できる「QFINDR」というサービスを運営しています。
広告クリエイティブの自動生成(Omneky)
ジェネレーティブAI広告プラットフォームのOmnekyが提供する自動広告生成ツール「Creative Assistant」においても、画像やテキスト、音声といった多彩なコンテンツの自動生成にChatGPTが活用されています。
[参考] GPTについてもっと学びたい人へ
GPTについてより知りたい方向けに、以下にいくつかの主要な論文とその要約を記載します。
GPT-4は、入力される画像とテキストから、テキストの出力を生成する大規模なマルチモーダルモデルです。現実世界の多くのシナリオにおいてまだその能力は人間より低いものの、学術的な評価テストなどでは人間レベルのパフォーマンスを示しており、模擬司法試験に合格するなどの成果を上げています。GPT-4はTransformerベースのモデルであり、文書内の次のトークンを予測するために事前にトレーニングされています。事後調整プロセスにより、事実性や所望の振る舞いに対する遵守度の評価を向上させることができます。このプロジェクトの中心的なコンポーネントは、広範なスケールにわたって予測可能な動作をするインフラストラクチャと最適化方法の開発でした。これにより、GPT-4の1/1,000分のコンピュートしか使用していないモデルを使用して、GPT-4のパフォーマンスの一部を正確に予測することができました。
・Language Models are Few-Shot Learners
最近の研究では、大規模なテキストコーパスでの事前学習と、特定のタスク向けのファインチューニングによって、多くのNLPタスクとベンチマークにおいて大きな進展が見られています。通常、アーキテクチャはタスクに依存しないものの、この方法には数千または数万のタスク特定の微調整データセットが必要です。これに対し、人間は一般的にわずかな例または単純な指示だけで新しい言語タスクを実行できますが、現在のNLPシステムはまだこれに苦労しています。ここでは、言語モデルのスケーリングがタスクに依存しないフューショットの性能を大幅に改善することを示します。先行研究の微調整アプローチと競合するレベルに達することもあります。具体的には、1750億のパラメータを持つオートレグレッシブ言語モデルであるGPT-3をトレーニングし、フューショットの環境でそのパフォーマンスをテストします。すべてのタスクにおいて、GPT-3は勾配の更新や微調整なしに適用され、タスクとフューショットデモンストレーションはモデルとのテキストインタラクションを通じて純粋に指定されます。GPT-3は、翻訳、質問応答、クローズタスクをはじめとする多数のNLPデータセットで強力なパフォーマンスを発揮し、また、単語のアンスクランブル、新しい単語を文に使う、3桁の算術を実行するなどのオンザフライの推論やドメイン適応が必要なタスクでも高い性能を示します。同時に、GPT-3のフューショット学習がまだ苦手なデータセットや、大規模なWebコーパスのトレーニングに関連する方法論的な問題があるデータセットも特定します。最後に、GPT-3は、人間の評価者が人間によって書かれた記事と区別がつかないようなニュース記事のサンプルを生成できることがわかります。
クイズ
人工知能基礎講座を提供中
サンプル動画

AI初学者・ビジネスパーソン向けのG検定対策講座

zero to oneの「E資格」向け認定プログラム
